This is the third in a series of posts on rocket science. Part I covered the history of rocketry and Part II dealt with the operating principles of rockets. If you have not checked out the latter post, I highly recommend you read this first before diving into what is to follow.
We have established that designing a powerful rocket means suspending a bunch of highly reactant chemicals above an ultralight means of combustion. In terms of metrics this means that a rocket scientist is looking to
- Maximise the mass ratio to achieve the highest amounts of delta-v. This translates to carrying the maximum amount of fuel with minimum supporting structure to maximise the achievable change in velocity of the rocket.
- Maximise the specific impulse of the propellant. The higher the specific impulse of the fuel the greater the exhaust velocity of the hot gases and consequently the greater the momentum thrust of the engine.
- Optimise the shape of the exhaust nozzle to produce the highest amounts of pressure thrust.
- Optimise the staging strategy to reach a compromise between the upside of staging in terms of shedding useless mass and the downside of extra technical complexity involved in joining multiple rocket engines (such complexity typically adds mass).
- Minimise the dry mass costs of the rocket either by manufacturing simple expendable rockets at scale or by building reusable rockets.
These operational principles set the landscape of what type of rocket we want to design. In designing chemical rockets some of the pertinent questions we need to answer are
- What propellants to use for the most potent reaction?
- How to expel and direct the exhaust gases most efficiently?
- How to minimise the mass of the structure?
Here, we will turn to the propulsive side of things and answer the first of these two questions.
Propellant
In a chemical rocket an exothermic reaction of typically two different chemicals is used to create high-pressure gases which are then directed through a nozzle and converted into a high-velocity directed jet.
From the Tsiolkovsky rocket equation we know that the momentum thrust depends on the mass flow rate of the propellants and the exhaust velocity,

The most common types of propellant are:
- Monopropellant: a single pressurised gas or liquid fuel that disassociates when a catalyst is introduced. Examples include hydrazine, nitrous oxide and hydrogen peroxide.
- Hypergolic propellant: two liquids that spontaneously react when combined and release energy without requiring external ignition to start the reaction.
- Fuel and oxidiser propellant: a combination of two liquids or two solids, a fuel and an oxidiser, that react when ignited. Combinations of solid fuel and liquid oxidiser are also possible as a hybrid propellant system. Typical fuels include liquid hydrogen and kerosene, while liquid oxygen and nitric acid are often used as oxidisers. In liquid propellant rockets the oxidiser and fuel are typically stored separately and mixed upon ignition in the combustion chamber, whereas solid propellant rockets are designed premixed.
Rockets can of course be powered by sources other than chemical reactions. Examples of this are smaller, low performance rockets such as attitude control thruster, that use escaping pressurised fluids to provide thrust. Similarly, a rocket may be powered by heating steam that then escapes through a propelling nozzle. However, the focus here is purely on chemical rockets.
Solid propellants
Solid propellants are made of a mixture of different chemicals that are blended into a liquid, poured into a cast and then cured into a solid. At its simplest, these chemical blends or “composites” are comprised of four different functional ingredients:
- Solid oxidiser granules.
- Flakes or powders of exothermic compounds.
- Polymer binding agent.
- Additives to stabilise or modify the burn rate.
Gunpowder is an example of a solid propellant that does not use a polymer binding agent to hold the propellant together. Rather the charcoal fuel and potassium nitrate oxidiser are compressed to hold their shape. A popular solid rocket fuel is ammonium perchlorate composite propellant (APCP) which uses a mixture of 70% granular ammonium perchlorate as an oxidiser, with 20% aluminium powder as a fuel, bound together using 10% polybutadiene acrylonitrile (PBAN).

Solid propellant rocket components (via Wikimedia Commons URL)
Solid propellant rockets have been used much less frequently than liquid fuel rockets. However, there are some advantages, which can make solid propellants favourable to liquid propellants in some military applications (e.g. intercontinental ballistic missiles, ICBMs). Some of the advantages of solid propellants are that:
- They are easier to store and handle.
- They are simpler to operate with.
- They have less components. There is no need for a separate combustion chamber and turbo pumps to pump the propellants into the combustion chamber. The solid propellant (also called “grain”) is ignited directly in the propellant storage casing.
- They are much denser than liquid propellants and therefore reduce the fuel tank size (lower mass). Furthermore, solid propellants can be used as a load-bearing component, which further reduces the structural weight of the rocket. The cured solid propellant can readily be encased in a filament-wound composite rocket shell, which has more favourable strength-to-weight properties of the metallic rocket shells typically used for liquid rockets.
Apart from their use as ICBMs, solid rockets are known for their role as boosters. The simplicity and relatively low cost compared with liquid-fuel rockets means that solid rockets are a better choice when large amounts of cheap additional thrust is required. For example, the Space Shuttle used two solid rocket boosters to complement the onboard liquid propellant engines.
The disadvantage of solid propellants is that their specific impulse, and hence the amount of thrust produced per unit mass of fuel, is lower than for liquid propellants. The mass ratio of solid rockets can actually be greater than that of liquid rockets as a result of the more compact design and lower structural mass, but the exhaust velocities are much lower. The combustion process in solid rockets depends on the surface area of the fuel, and as such any air bubbles, cracks or voids in the solid propellant cast need to be prevented. Therefore, quite expensive quality assurance measures such as ultrasonic inspection or x-rays are required to assure the quality of the cast. The second problem with air bubbles in the cast is that the amount of oxidiser is increased (via the oxygen in the air) which results in local temperature hot spots and increased burn rate. Such local imbalances can spiral out of control to produce excessive temperatures and pressures, and ultimately lead to catastrophic failure. Another disadvantage of solid propellants are their binary operation mode. Once the chemical reaction has started and the engines have been ignited, it is very hard to throttle back or control the reaction. The propellant can be arranged in a manner to provide a predetermined thrust profile, but once this has started it is much hard to make adjustments on the fly. Liquid propellant rockets on the other hand use turbo pumps to throttle the propellant flow.
Liquid propellants
Liquid propellants have more favourable specific impulse measures than solid rockets. As such they are more efficient at propelling the rocket for a unit mass of reactant mass. This performance advantage is due to the superior oxidising capabilities of liquid oxidisers. For example, traditional liquid oxidisers such as liquid oxygen or hydrogen peroxide result in higher specific impulse measures than the ammonium perchlorate in solid rockets. Furthermore, as the liquid fuel and oxidiser are pumped into the combustion chamber, a liquid-fuelled rocket can be throttled, stopped and restarted much like a car or a jet engine. In liquid-fuelled rockets the combustion process is restricted to the combustion chamber, such that only this part of the rocket is exposed to the high pressure and temperature loads, whereas in solid-fuelled rockets the propellant tanks themselves are subjected to high pressures. Liquid propellants are also cheaper than solid propellants as they can be sourced from the upper atmosphere and require relatively little refinement compared to the composite manufacturing process of solid propellants. However, the cost of the propellant only accounts for around 10% of the total cost of the rocket and therefore these savings are typically negligible. Incidentally, the high proportion of costs associated with the structural mass of the rocket is why re-usability of rocket stages is such an important factor in reducing the cost of spaceflight.

Schematic of a liquid-fuelled rocket (via Wikimedia Commons)
Modern spaceflight is dominated by two liquid propellant mixtures:
- Liquid oxygen (LOX) and kerosene (RP-1): As discussed in the previous post this mix of oxidiser and fuel is predominantly used for lower stages (i.e. to get off the launch pad), due to the higher density of kerosene compared to liquid hydrogen. Kerosene, as a higher density fuel, allows for better ratios of propellant to tankage mass which is favourable for the mass ratio. Second, high density fuels work better in an atmospheric pressure environment. Historically, the Atlas V, Saturn V and Soyuz rockets have used LOX and RP-1 for the first stages and so does the SpaceX Falcon rocket today.
- Liquid oxygen and liquid hydrogen: This combination is mostly used for the upper stages that propel a vehicle into orbit. The lower density of the liquid hydrogen requires higher expansion ratios (gas pressure – atmospheric pressure) and therefore works more efficiently at higher altitudes. The Atlas V, Saturn V and modern Delta family or rockets all used this propellant mix for the upper rocket stages.
The choice of propellant mixture for different stages requires certain tradeoffs. Liquid hydrogen provides higher specific impulse than kerosene, but its density is around 7 times lower and therefore liquid hydrogen occupies much more space for the same mass of fuel. As a result, the required volume and associated mass of tankage, fuel pumps and pipes is much greater. Both the the specific impulse of the propellant and tankage mass influence the potential delta-v of the rocket, and hence liquid hydrogen, chemically the more efficient fuel, is not necessarily the best option for all rockets.
Although the exact choice of fuel is not straightforward I will propose two general rules of thumb that explain why kerosene is used for the early stages and liquid hydrogen for the upper stages:
- In general, the denser the fuel the heavier the rocket on the launch pad. This means that the rocket needs to provide more thrust to get off the ground and it carries this greater amount of thrust throughout the entire duration of the burn. As fuel is being depleted, the greater thrust of denser fuel rockets means that the rocket reaches orbit earlier and as a result minimises drag losses in the atmosphere.
- Liquid hydrogen fuelled rockets generally produce the lightest design and are therefore used on those parts of the spacecraft that actually need to be propelled into orbit or escape Earth’s gravity to venture into deep space.
Engine and Nozzle
In combustive rockets, the chemical reaction between the fuel and oxidiser creates a high temperature, high pressure gas inside the combustion chamber. If the combustion chamber were closed and symmetric, the internal pressure acting on the chamber walls would cause equal force in all directions and the rocket would remain stationary. For anything interesting to happen we must therefore open one end of the combustion chamber to allow the hot gases to escape. As a result of the hot gases pressing against the wall opposite to the opening, a net force in the direction of the closed end is induced.

Net thrust produced by rocket (via Wikimedia Commons)
To further accelerate the flow, a divergent nozzle is required at the choke point. A convergent-divergent nozzle can therefore be used to create faster fluid flows. Crucially, the Tsiolkovsky rocket equation (conservation of momentum) indicates that the exit velocity of the hot gases is directly proportional to the amount of thrust produced. A second advantage is that the escaping gases also provide a force in the direction of flight by pushing on the divergent section of the nozzle.

Underexpanded, perfectly expanded, overexpanded and grossly overexpanded de Laval nozzles (via Wikimedia Commons).
In an ideal world a rocket would continuously operate at peak efficiency, the condition where the nozzle is perfectly expanded throughout the entire flight. This can intuitively be explained using the rocket thrust equation introduced in the previous post:

Peak efficiency of the rocket engine occurs when 
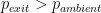
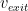


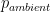

A perfectly expanded nozzle is only possible using a variable throat area or variable exit area nozzle to counteract the ambient pressure decrease with gaining altitude. As a result, fixed area nozzles become progressively underexpanded as the ambient pressure decreases during flight, and this means most nozzles are grossly overexpanded at takeoff. Some various exotic nozzles such as plug nozzles, stepped nozzles and aerospikes have been proposed to adapt to changes in ambient pressure and increasing thrust at higher altitudes. The extreme scenario obviously occurs once the rocket has left the Earth’s atmosphere. The nozzle is now so grossly overexpanded that the extra weight of the nozzle structure outweighs any performance gained from the divergent section.
Thus we can see that just as in the case of the propellants the design of individual components is not a straightforward matter and requires detailed tradeoffs between different configurations. This is what makes rocket science such a difficult endeavour.
In a previous post we covered the history of rocketry over the last 2000 years. By means of the Tsiolkovsky rocket equation we also established that the thrust produced by a rocket is equal to the mass flow rate of the expelled gases multiplied by their exit velocity. In this way, chemically fuelled rockets are much like traditional jet engines: an oxidising agent and fuel are combusted at high pressure in a combustion chamber and then ejected at high velocity. So the means of producing thrust are similar, but the mechanism varies slightly:
- Jet engine: A multistage compressor increases the pressure of the air impinging on the engine nacelle. The compressed air is mixed with fuel and then combusted in the combustion chamber. The hot gases are expanded in a turbine and the energy extracted from the turbine is used to power the compressor. The mass flow rate and velocity of the gases leaving the jet engine determine the thrust.
- Chemical rocket engine: A rocket differs from the standard jet engine in that the oxidiser is also carried on board. This means that rockets work in the absence of atmospheric oxygen, i.e. in space. The rocket propellants can be in solid form ignited directly in the propellant storage tank, or in liquid form pumped into a combustion chamber at high pressure and then ignited. Compared to standard jet engines, rocket engines have much higher specific thrust (thrust per unit weight), but are less fuel efficient.
![A turbojet engine [1].](https://aerospaceengineeringblog.com/wp-content/uploads/2016/04/JetEngine.jpg)
A turbojet engine [1].
![A liquid propellant rocket engine [1].](https://aerospaceengineeringblog.com/wp-content/uploads/2016/04/RocketEngine.jpg)
A liquid propellant rocket engine [1].
In this post we will have a closer look at the operating principles and equations that govern rocket design. An introduction to rocket science if you will…
The fundamental operating principle of rockets can be summarised by Newton’s laws of motion. The three laws:
- Objects at rest remain at rest and objects in motion remain at constant velocity unless acted upon by an unbalanced force.
- Force equals mass times acceleration (or
).
- For every action there is an equal and opposite reaction.
are known to every high school physics student. But how exactly to they relate to the motion of rockets?
Let us start with the two qualitative equations (the first and third laws), and then return to the more quantitative second law.
Well, the first law simply states that to change the velocity of the rocket, from rest or a finite non-zero velocity, we require the action of an unbalanced force. Hence, the thrust produced by the rocket engines must be greater than the forces slowing the rocket down (friction) or pulling it back to earth (gravity). Fundamentally, Newton’s first law applies to the expulsion of the propellants. The internal pressure of the combustion inside the rocket must be greater than the outside atmospheric pressure in order for the gases to escape through the rocket nozzle.
A more interesting implication of Newton’s first law is the concept escape velocity. As the force of gravity reduces with the square of the distance from the centre of the earth (
At face value, Newton’s third law, the principle of action and reaction, is seemingly intuitive in the case of rockets. The action is the force of the hot, highly directed exhaust gases in one direction, which, as a reaction, causes the rocket to accelerate in the opposite direction. When we walk, our feet push against the ground, and as a reaction the surface of the Earth acts against us to propel us forward.
So what does a rocket “push” against? The molecules in the surrounding air? But if that’s the case, then why do rockets work in space?
The thrust produced by a rocket is a reaction to mass being hurled in one direction (i.e. to conserve momentum, more on that later) and not a result of the exhaust gases interacting directly with the surrounding atmosphere. As the rockets exhaust is entirely comprised of propellant originally carried on board, a rocket essentially propels itself by expelling parts of its mass at high speed in the opposite direction of the intended motion. This “self-cannibalisation” is why rockets work in the vacuum of space, when there is nothing to push against. So the rocket doesn’t push against the air behind it at all, even when inside the Earth’s atmosphere.
Newton’s second law gives us a feeling for how much thrust is produced by the rocket. The thrust is equal to the mass of the burned propellants multiplied by their acceleration. The capability of rockets to take-off and land vertically is testament to their high thrust-to-weight ratios. Compare this to commercial jumbo or military fighter jets which use jet engines to produce high forward velocity, while the upwards lift is purely provided by the aerodynamic profile of the aircraft (fuselage and wings). Vertical take-off and landing (VTOL) aircraft such as the Harrier Jump jet are the rare exception.
At any time during the flight, the thrust-to-weight ratio is equal to the acceleration of the rocket. From Newton’s second law,

where 


However, Newton’s second law only applies to each instantaneous moment in time. It does not allow us to make predictions of the rocket velocity as fuel is depleted. Mass is considered to be constant in Newton’s second law, and therefore it does not account for the fact that the rocket accelerates more as fuel inside the rocket is depleted.
The rocket equation
The Tsiolkovsky rocket equation, however, takes this into account. The motion of the rocket is governed by the conservation of momentum. When the rocket and internal gases are moving as one unit, the overall momentum, the product of mass and velocity, is equal to 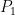

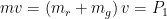
As the gases are expelled through the rear of the rocket, the overall momentum of the rocket and fuel has to remain constant as long as no external forces act on the system. Thus, if a very small amount of gas 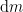
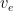

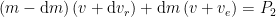
As 
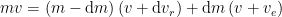
and by isolating the change in rocket velocity

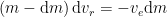

The negative sign in the equation above indicates that the rocket always changes velocity in the opposite direction of the expelled gas, as intuitively expected. So if the gas is expelled in the opposite direction of the rocket motion
At any time 

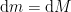

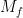
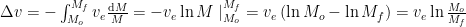
This equation is known as the Tsiolkovsky rocket equation and is applicable to any body that accelerates by expelling part of its mass at a specific velocity. Even though the expulsion velocity may not remain constant during a real rocket launch we can refer to an effective exhaust velocity that represent a mean value over the course of the flight.
The Tsiolkovsky rocket equation shows that the change in velocity attainable is a function of the exhaust jet velocity and the ratio of original take-off mass (structural weight + fuel = 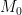
In a nutshell, the greater the ratio of fuel to structural mass, the more propellant is available to accelerate the rocket and therefore the greater the maximum velocity of the rocket.
So in the ideal case we want a bunch of highly reactant chemicals magically suspended above an ultralight means of combusting said fuel.
In reality this means we are looking for a rocket propelled by a fuel with high efficiency of turning chemical energy into kinetic energy, contained within a lightweight tankage structure and combusted by a lightweight rocket engine. But more on that later!
Thrust
Often, we are more interested in the thrust created by the rocket and its associated acceleration 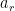

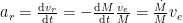
and the associated thrust 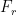

where 

where 
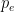
This equation provides some additional physical insight. The term 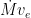
Impulse and specific impulse
The overall amount of thrust is typically not used as an indicator for rocket performance. Better indicators of an engine’s performance are the total and specific impulse figures. Ignoring any external forces (gravity, drag, etc.) the impulse is equal to the change in momentum of the rocket (mass times velocity) and is therefore a better metric to gauge how much mass the rocket can propel and to what maximum velocity. For a change in momentum 
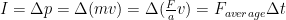
So to maximise the impulse imparted on the rocket we want to maximise the amount of thrust 
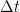
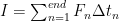
Therefore, impulse is additive and the total impulse of a multistage rocket is equal to the sum of the impulse imparted by each individual stage.
By specific impulse we mean the net impulse imparted by a unit mass of propellant. It’s the efficiency with which combustion of the propellant can be converted into impulse. The specific impulse is therefore a metric related to a specific propellant system (fuel + oxidiser) and essentially normalises the exhaust velocity by the acceleration of gravity that it needs to overcome:

where 

A typical liquid hydrogen/liquid oxygen rocket will achieve an
Delta-v and mass ratios
The Tsiolkovsky rocket equation can be used to calculate the theoretical upper limit in total velocity change, called delta-v, for a certain amount of propellant mass burn at a constant exhaust velocity

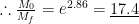
to reach LEO. This means that the original rocket on the launch pad is 17.4 times heavier than when all the rocket fuel is depleted!
Just to put this into perspective, this means that the mass of fuel inside the rocket is SIXTEEN times greater than the dry structural mass of tanks, payload, engine, guidance systems etc. That’s a lot of fuel!

Delta-v figures required for rendezvous in the solar system. Note the delta-v to get to the Moon is approximately 10 + 4.1 + 0.7 + 1.6 = 16.4 km/s and thus requires a whopping mass ratio of 108.4 at an effective exhaust velocity of 3500 m/s.

is known as the mass ratio. In some cases, the reciprocal of the mass ratio is used to calculate the mass fraction:

The mass fraction is necessarily always smaller than 1, and in the above case is equal to 
So 94% of this rocket’s mass is fuel!
Such figures are by no means out of the ordinary. In fact, the Space Shuttle had a mass ratio in this ballpark (15.4 = 93.5% fuel) and Europe’s Ariane V rocket has a mass ratio of 39.9 (97.5% fuel).
If anything, flying a rocket means being perched precariously on top of a sea of highly explosive chemicals!
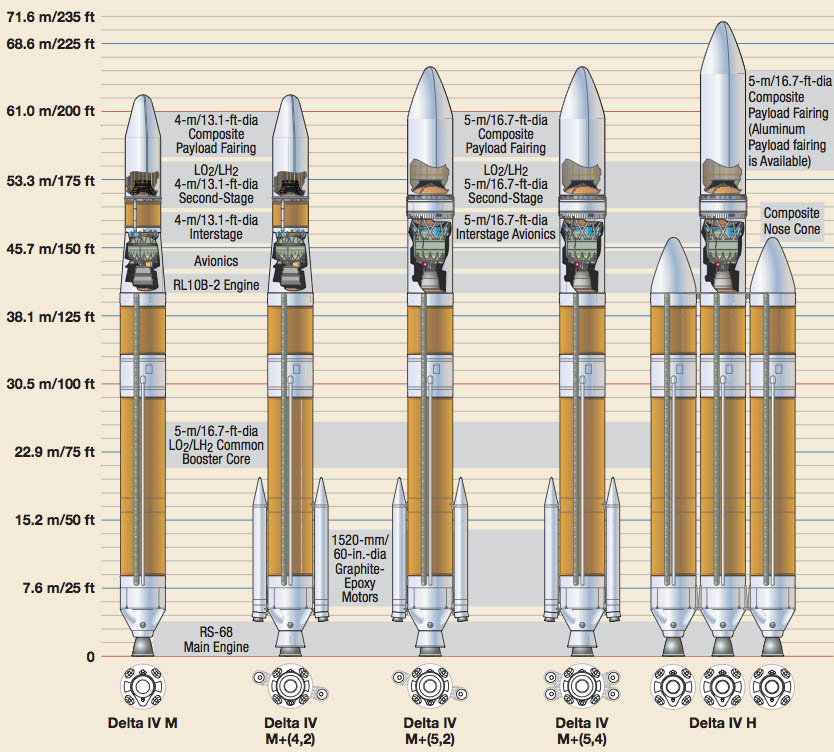
The reason for the incredibly high amount of fuel is the exponential term in the above equation. The good thing is that adding fuel means we have an exponential law working in our favour: For each extra gram of fuel we can pack into the rocket we get a superlinear (better than linear) increase in delta-v. On the downside, for every piece of extra equipment, e.g. payload, we stick into the rocket we get an equally exponential reduction in delta-v.
In reality, the situation is obviously more complex. The point of a rocket is to carry a certain payload into space and the distance we want to travel is governed by a specific amount of delta-v (see figure to the right). For example, getting to the Moon requires a delta-v of approximately 16.4 km/s which implies a whopping mass ratio of 108.4. Therefore, if we wish to increase the payload mass, we need to simultaneously increase propellant mass to keep the mass ratio at 108.4. However, increasing the amount of fuel increases the loads acting on the rocket, and therefore more structural mass is required to safely get the rocket to the Moon. Of course, increasing structural mass similarly increases our fuel requirement, and off we go on a nice feedback loop…
This simple example explains why the mass ratio is a key indicator of a rocket’s structural efficiency. The higher the mass ratio the greater the ratio of delta-v producing propellant to non-delta-v producing structural mass. All other factors being equal, this suggests that a high mass ratio rocket is more efficient because less structural mass is needed to carry a set amount of propellant.
The optimal rocket is therefore propelled by high specific impulse fuel mixture (for high exhaust velocity), with minimal structural requirements to contain the propellant and resist flight loads, and minimal requirements for additional auxiliary components such as guidance systems, attitude control, etc.
For this reason, early rocket stages typically use high-density propellants. The higher density means the propellants take up less space per unit mass. As a result, the tank structure holding the propellant is more compact as well. For example, the Saturn V rocket used the slightly lower specific impulse combination of kerosene and liquid oxygen for the first stage, and the higher specific impulse propellants liquid hydrogen and liquid oxygen for later stages.
Closely related to this, is the idea of staging. Once, a certain amount of fuel within the tanks has been used up, it is beneficial to shed the unnecessary structural mass that was previously used to contain the fuel but is no longer contributing to delta-v. In fact, for high delta-v missions, such as getting into orbit, the total dry-mass of the rockets we use today is too great to be able to accelerate to the desired delta-v. Hence, the idea of multi-stage rockets. We connect multiple rockets in stages, incrementally discarding those parts of the structural mass that are no longer needed, thereby increasing the mass ratio and delta-v capacity of the residual pieces of the rocket.
Cost
The cost of getting a rocket on to the launch pad can roughly be split into three components:
- Propellant cost.
- Cost of dry mass, i.e. rocket casing, engines and auxiliary units.
- Operational and labour costs.
As we saw in the last section, more than 90% of a rocket take-off mass is propellant. However, the specific cost (cost per kg) of the propellants is multiple orders of magnitude smaller than the cost per unit mass of the rocket dry mass mass, i.e. the raw material costs and operational costs required to manufacture and test them. A typical propellant combination of kerosene and liquid oxygen costs around $2/kg, whereas the dry mass cost of an unmanned orbital vehicle is at least $10,000/kg. As a result, the propellant cost of flying into low earth orbit is basically negligible.
The incredibly high dry mass costs are not necessarily because the raw material, predominantly high-grade aerospace metals, are prohibitively expense, rather they cannot be bought at scale because of the limited number of rockets being manufactured. Second, the criticality of reducing structural mass for maximising delta-v means that very tight safety factors are employed. Operating a tight safety factor design philosophy while ensuring sufficient safety and reliability standards under the extreme load conditions exerted on the rocket means that manufacturing standards and quality control measures are by necessity state-of-the-art. Such procedures are often highly specialised technologies that significantly drive up costs.
To clear these economic hurdles, some have proposed to manufacture simple expendable rockets at scale, while others are focusing on reusable rockets. The former approach will likely only work for unmanned smaller rockets and is being pursued by companies such as Rocket Lab Ltd. The Space Shuttle was an attempt at the latter approach that did not live up to its potential. The servicing costs associated with the reusable heat shield were unexpectedly high and ultimately forced the retirement of the Shuttle. Most, recently Elon Musk and SpaceX have picked up the ball and have successfully designed a fully reusable first stage.
The principles outlined above set the landscape of what type of rocket we want to design. Ideally, a high specific impulse chemicals suspended in a lightweight yet strong tankage structure above an efficient means of combustion.
Some of the more detailed questions rocket engineers are faced with are:
- What propellants to use to do the job most efficiently and at the lowest cost?
- How to expel and direct the exhaust gases most efficiently?
- How to control the reaction safely?
- How to minimise the mass of the structure?
- How to control the attitude and accuracy of the rocket?
We will address these questions in the next part of this series.
References
[1] Rolls-Royce plc (1996). The Jet Engine. Fifth Edition. Derby, England.
Rocket technology has evolved for more than 2000 years. Today’s rockets are a product of a long tradition of ingenuity and experimentation, and combine technical expertise from a wide array of engineering disciplines. Very few, if any, of humanity’s inventions are designed to withstand equally extreme conditions. Rockets are subjected to awesome g-forces at lift-off, and experience extreme hot spots in places where aerodynamic friction acts most strongly, and extreme cold due to liquid hydrogen/oxygen at cryogenic temperatures. Operating a rocket is a balance act, and the line between a successful launch and catastrophic blow-out is often razor thin. No other engineering system rivals the complexity and hierarchy of technologies that need to interface seamlessly to guarantee sustained operation. It is no coincidence that “rocket science” is the quintessential cliché to describe the mind-blowingly complicated.
Fortunately for us, we live in a time where rocketry is undergoing another golden period. Commercial rocket companies like SpaceX and Blue Origin are breathing fresh air into an industry that has traditionally been dominated by government-funded space programs. But even the incumbent companies are not resting on their laurels, and are developing new powerful rockets for deep-space exploration and missions to Mars. Recent blockbuster movies such as Gravity, Interstellar and The Martian are an indication that space adventures are once again stirring the imagination of the public.
What better time than now to look back at the past 2000 years of rocketry, investigate where past innovation has taken us and look ahead to what is on the horizon? It’s certainly impossible to cover all of the 51 influential rockets in the chart below but I will try my best to provide a broad brush stroke of the early beginnings in China to the Space Race and beyond.

51 influential rockets ordered by height. Created by Tyler Skrabek
The history of rocketry can be loosely split into two eras. First, early pre-scientific tinkering and second, the post-Enlightenment scientific approach. The underlying principle of rocket propulsion has largely remained the same, whereas the detailed means of operation and our approach to developing rocketry has changed a great deal.

An illustration of Hero’s aeolipile
In both these examples, the motion of the device is governed by the conservation of momentum. When the rocket and internal gases are moving as one unit, the overall momentum, the product of mass and velocity, is equal to
As the gases are expelled through the rear of the rocket, the overall momentum of the rocket and fuel has to remain constant as long as no external forces are acting on the system. Thus, if a very small amount of gas
As
and by isolating the change in rocket velocity
The negative sign in the equation above indicates that the rocket always changes velocity in the opposite direction of the expelled gas. Hence, if the gas is expelled in the opposite direction of the motion
At any time
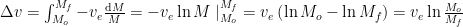
This equation is known as the Tsiolkovsky rocket equation (more on him later) and is applicable to any body that accelerates by expelling part of its mass at a specific velocity.
Often, we are more interested in the thrust created by the rocket and its associated acceleration 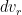
and the associated thrust
where
A plot of the rocket equation highlights one of the most pernicious conundrums of rocketry: The amount of fuel required (i.e. the mass ratio 



The exponential increase of fuel mass required to accelerate a rocket through a specific velocity change

Drawing of a Chinese rocket and launching mechanism
The first documented use of such a “true” rocket was during the battle of Kai-Keng between the Chinese and Mongols in 1232. During this battle the Chinese managed to hold the Mongols at bay using a primitive form a solid-fueled rocket. A hollow tube was capped at one end, filled with gunpowder and then attached to a long stick. The ignition of the gunpowder increased the pressure inside the hollow tube and forced some of the hot gas and smoke out through the open end. As governed by the law of conservation of momentum, this creates thrust to propel the rocket in the direction of the capped end of the tube, with the long stick acting as a primitive guidance system, very much reminiscent of the firework “rockets” we use today.

Wan Hu (the man in the moon?) and his rocket chair
According to a Chinese legend, Wan Hu, a local official during the 16th century Ming dynasty, constructed a chair with 47 gunpowder bamboo rockets attached, and in some versions of the legend supposedly fitted kite wings as well. The rocket chair was launched by igniting all 47 bamboo rockets simultaneously, and apparently, after the commotion was over, Wan Hu was gone. Some say he made it into space, and is now the “Man in the Moon”. Most likely, Wan Hu suffered the first ever launch pad failure.
One theory is that rockets were brought to Europe via the 13th cetnury Mongol conquests. In England, Roger Bacon developed a more powerful gunpowder (75% saltpetre, 15% carbon and 10% sulfur) that increased the range of rockets, while Jean Froissart added a launch pad by launching rockets through tubes to improve aiming accuracy. By the Renaissance, the use of rockets for weaponry fell out of fashion and experimentation with fireworks increased instead. In the late 16th century, a German tinkerer, Johann Schmidlap, experimented with staged rockets, an idea that is the basis for all modern rockets. Schmidlap fitted a smaller second-stage rocket on top of a larger first-stage rocket, and once the first stage burned out, the second stage continued to propel the rocket to higher altitudes. At about the same time, Kazimierz Siemienowicz, a Polish-Lithuanian commander in the Polish Army published a manuscript that included a design for multi-stage rockets and delta-wing stabilisers that were intended to replace the long rods currently acting as stabilisers.
The scientific method meets rocketry
The scientific groundwork of rocketry was laid during the Enlightenment by none other than Sir Isaac Newton. His three laws of motion,
1) In a particular reference frame, a body will stay in a state of constant velocity (moving or at rest) unless a net force is acting on the body
2) The net force acting on a body causes an acceleration that is proportional to the body’s inertia (mass), i.e. F=ma
3) A force exerted by one body on another induces an equal an opposite reaction force on the first body
are known to every student of basic physics. In fact, these three laws were probably intuitively understood by early rocket designers, but by formalising the principles, they were consciously being used as design guidelines. The first law explains why rockets move at all. Without creating propulsive thrust the rocket will remain stationary. The second quantifies the amount of thrust produced by a rocket at a specific instant in time, i.e. for a specific mass 
In the 1720s, at around the time of Newton’s death, researchers in the Netherlands, Germany and Russia started to use Newton’s laws as tools in the design of rockets. The dutch professor Willem Gravesande built rocket-propelled cars by forcing steam through a nozzle. In Germany and Russia rocket designers started to experiment with larger rockets. These rockets were powerful enough that the hot exhaust flames burnt deep holes into the ground before launching. The British colonial wars of 1792 and 1799 saw the use of Indian rocket fire against the British army. Hyder Ali and his son Tipu Sultan, the rulers of the Kingdom of Mysore in India, developed the first iron-cased rockets in 1792 and then used it against the British in the Anglo-Mysore Wars.
Casing the propellant in iron, which extended range and thrust, was more advanced technology than anything the British had seen until then, and inspired by this technology, the British Colonel William Congreve began to design his own rocket for the British forces. Congreve developed a new propellant mixture and fitted an iron tube with a conical nose to improve aerodynamics. Congreve’s rockets had an operational range of up to 5 km and were successfully used by the British in the Napoleonic Wars and launched from ships to attack Fort McHenry in the War of 1812. Congreve created both carbine ball-filled rockets to be used against land targets, and incendiary rockets to be used against ships. However, even Congreve’s rockets could not significantly improve on the main shortcomings of rockets: accuracy.

A selection of Congreve rockets
At the time, the effectiveness of rockets as a weapon was not their accuracy or explosive power, but rather the sheer number that could be fired simultaneously at the enemy. The Congreve rockets had managed some form of basic attitude control by attaching a long stick to the explosive, but the rockets had a tendency to veer sharply off course. In 1844, a British designer, William Hale developed spin stabilisation, now commonly used in gun barrels, which removed the need for the rocket stick. William Hale forced the escaping exhaust gases at the rear of the rocket to impinge on small vanes, causing the rocket to spin and stabilise (the same reason that a gyroscope remains upright when spun on a table top). The use of rockets in war soon took a back seat once again when the Prussian army developed the breech-loading cannon with exploding warheads that proved far superior than the best rockets.
The era of modern rocketry
Soon, new applications for rockets were being imagined. Jules Verne, always the visionary, put the dream of space flight into words in his science-fiction novel “De la Terre á la Lune” (From the Earth to the Moon), in which a projectile, named Columbiad, carrying three passengers is shot at the moon using a giant cannon. The Russian schoolteacher Konstantin Tsiolkovsky (of rocket equation fame) proposed the idea of using rockets as a vehicle for space exploration but acknowledged that the main bottlenecks of achieving such a feat would require significant developments in the range of rockets. Tsiolkovsky understood that the speed and range of rockets was limited by the exhaust velocity of the propellant gases. In a 1903 report, “Research into Interplanetary Space by Means of Rocket Power”, he suggested the use of liquid-propellants and formalised the rocket equation derived above, relating the rocket engine exhaust velocity to the change in velocity of the rocket itself (now known as the Tsiolkovsky rocket equation in his honour, although it had already been discovered previously).
Tsiolkovsky also advocated the development of orbital space stations, solar energy and the colonisation of the Solar System. One of his quotes is particularly prescient considering Elon Musk’s plans to colonise Mars:
“The Earth is the cradle of humanity, but one cannot live in the cradle forever” — In a letter written by Tsiolkovsky in 1911.
The American scientist Robert H. Goddard, now known as the father of modern rocketry, was equally interested in extending the range of rockets, especially reaching higher altitudes than the gas balloons used at the time. In 1919 he published a short manuscript entitled “A Method of Reaching Extreme Altitudes” that summarised his mathematical analysis and practical experiments in designing high altitude rockets. Goddard proposed three ways of improving current solid-fuel technology. First, combustion should be contained to a small chamber such that the fuel container would be subjected to much lower pressure. Second, Goddard advocated the use of multi-stage rockets to extend their range, and third, he suggested the use of a supersonic de Laval nozzle to improve the exhaust speed of the hot gases.
Goddard started to experiment with solid-fuel rockets, trying various different compounds and measuring the velocity of the exhaust gases. As a result of this work, Goddard was convinced of Tsiolkovsky’s early premonitions that a liquid-propellant would work better. The problem that Goddard faced was that liquid-propellant rockets were an entirely new field of research, no one had ever built one, and the system required was much more complex than for a solid-fuelled rocket. Such a rocket would need separate tanks and pumps for the fuel and oxidiser, a combustion chamber to combine and ignite the two, and a turbine to drive the pumps (much like the turbine in a jet engine drives the compressor at the front). Goddard also added a de Laval nozzle which cooled the hot exhaust gases into a hypersonic, highly directed jet, more than doubling the thrust and increasing engine efficiency from 2% to 64%! Despite these technical challenges, Goddard designed the first successful liquid-fuelled rocket, propelled by a combination of gasoline as fuel and liquid oxygen as oxidiser, and tested it on March 16, 1926. The rocket remained lit for 2.5 seconds and reached an altitude of 12.5 meters. Just like the first 40 yard flight of the Wright brothers in 1903, this feat seems unimpressive by today’s standards, but Goddard’s achievements put rocketry on an exponential growth curve that led to radical improvements over the next 40 years. Goddard himself continued to innovate; his rockets flew to higher and higher altitudes, he added a gyroscope system for flight control and introduced parachute recovery systems.
On the other side of the Atlantic, German scientists were beginning to play a major role in the development of rockets. Inspired by Hermann Oberth’s ideas on rocket travel, the mathematics of spaceflight and the practical design of rockets published in his book “Die Rakete zu den Planetenraumen” (The Rocket to Space), a number of rocket societies and research institutes were founded in Germany. The German bicycle and car manufacturer Opel (now part of GM) began developing rocket powered cars, and in 1928 Fritz von Opel drove the Opel-RAK.1 on a racetrack. In 1929 this design was extended to the Opel-Sander RAK 1-airplane, which crashed during its first flight in Frankfurt. In the Soviet Union, the Gas dynamics Laboratory in Leningrad under the directorship of Valentin Glushko built more than 100 different engine designs, experimenting with different fuel injection techniques.

A cross-section of the V-2 rocket
Under the directorship of Wernher von Braun and Walter Dornberger, the Verein for Raumschiffahrt or Society for Space Travel played a pivotal role in the development of the Vergeltungswaffe 2, also known as the V-2 rocket, the most advanced rocket of its time. The V-2 rocket burned a mixture of alcohol as fuel and liquid oxygen as oxidiser, and it achieved great amounts of thrust by considerably improving the mass flow rate of fuel to about 150 kg (380 lb) per second. The V-2 featured much of the technology we see on rockets today, such as turbo pumps and guidance systems, and due to its range of around 300 km (190 miles), the V-2 could be launched from the shores of the Baltic to bomb London during WWII. The 1000 kg (2200 lb) explosive warhead fitted in the tip of the V-2 was capable of devastating entire city blocks, but still lacked the accuracy to reliably hit specific targets. Towards the end of WWII, German scientists were already planning much larger rockets, today known as Intercontinental Ballistic Missiles (ICBMs), that could be used to attack the United States, and were strapping rockets to aircraft either for powering them or for vertical take-off.
With the fall of the Third Reich in April 1945 a lot of this technology fell into the hands of the Allies. The Allies’ rocket program was much less sophisticated such that a race ensued to capture as much of the German technology as possible. The Americans alone captured 300 train loads of V-2 rocket parts and shipped them back to the United States. Furthermore, the most prominent of the German rocket scientists emigrated to the United States, partly due to the much better opportunities to develop rocketry there, and partly to escape the repercussions of having played a role in the Nazi war machine. The V-2 essentially evolved into the American Redstone rocket which was used during the Mercury project.
The Space Race – to the moon and beyond
After WWII both the United States and the Soviet Union began heavily funding research into ICBMs, partly because these had the potential to carry nuclear warheads over long distances, and partly due to the allure of being the first to travel to space. In 1948, the US Army combined a captured V-2 rocket with a WAC Corporal rocket to build the largest two-stage rocket to be launched in the United States. This two-stage rocket was known as the “Bumper-WAC”, and over course of six flights reached a peak altitude of 400 kilometres (250 miles), pretty much exactly to the altitude where the International Space Station (ISS) orbits today.

The Vostok rocket based on the R-7 ICBM
One of the problems that the Soviets did not solve was atmospheric re-entry. Any object wishing to orbit another planet requires enough speed such that the gravitational attraction towards the planet is offset by the curvature of planet’s surface. However, during re-entry, this causes the orbiting body to literally smash into the atmosphere creating incredible amounts of heat. In 1951, H.J. Allen and A.J. Eggers discovered that a high drag, blunted shape, not a low-drag tear drop, counter-intuitively minimises the re-entry effects by redirecting 99% of the energy into the surrounding atmosphere. Allen and Eggers’ findings were published in 1958 and were used in the Mercury, Gemini, Apollo and Soyuz manned space capsules. This design was later improved upon in the Space Shuttle, whereby a shock wave was induced on the heat shield of the Space Shuttle via an extremely high angle of attack, in order to deflect most of the heat away from the heat shield.
The United States’ first satellite, Explorer I, would not follow until January 31, 1958. Explorer I weighed about 30 times less than the Sputnik II satellite, but the Geiger radiation counters on the satellite were used to make the first scientific discovery in outer space, the Van Allen Radiation Belts. Explorer I had originally been developed as part of the US Army, and in October 1958 the National Advisory Committee for Aeronautics (NACA, now NASA) was officially formed to oversee the space program. Simultaneously, the Soviets developed the Vostok, Soyuz and Proton family of rockets from the original R-7 ICBM to be used for the human spaceflight programme. In fact, the Soyuz rocket is still being used today, is the most frequently used and reliable rocket system in history, and after the Space Shuttle’s retirement in 2011 became the only viable means of transport to the ISS. Similarly, the Proton rocket, also developed in the 1960s, is still being used to haul heavier cargo into low-Earth orbit.

The Soyuz rocket in transport to the launch site
Shortly after these initial satellite launches, NASA developed the experimental X-15 air-launched rocket-propelled aircraft, which, in 199 flights between 1959 and 1968, broke numerous flying records, including new records for speed (7,274 kmh or 4,520 mph) and altitude records (108 kmh or 67 miles). The X-15 also provided NASA with data regarding the optimal re-entry angles from space into the atmosphere.
The next milestone in the space race once again belonged to the Soviets. On April 12, 1961, the cosmonaut Yuri Gagarin became the first human to travel into space, and as a result became an international celebrity. Over a period of just under two hours, Gagarin orbited the Earth inside a Vostok 1 space capsule at around 300 km (190 miles) altitude, and after re-entry into the atmosphere ejected at an altitude of 6 km (20,000 feet) and parachuted to the ground. At this point Gagarin became the most famous Soviet on the planet, travelling around the world as a beacon of Soviet success and superiority over the West.
Shortly after Gagarin’s successful flight, the American astronaut Alan Shepherd reached a suborbital altitude of 187 km (116 miles) in the Freedom 7 Mercury capsule. The Redstone ICBM that was used to launch Shephard from Cape Caneveral did not quite have the power to send the Mercury capsule into orbit, and had suffered a series of emberrassing failures prior to the launch, increasing the pressure on the US rocket engineers. However, days after Shephard’s flight, President John F. Kennedy delivered the now famous words before a joint session in Congress
“This nation should commit itself to achieving the goal, before this decade is out, of landing a man on the Moon and returning him safely to the Earth.”
Despite the bold nature of this challenge, NASA’s Mercury project was already well underway in developing the technology to put the first human on the moon. In February 1962, the more powerful Atlas missile propelled John Glenn into orbit, and thereby restored some form of parity between the USA and the Soviet Union. The last of the Mercury flights were scheduled for 1963 with Gordon Cooper orbiting the Earth for nearly 1.5 days. The family of Atlas rockets remains one of the most successful to this day. Apart from launching a number of astronauts into space during the Mercury project, the Atlas has been used for bringing commercial, scientific and military satellites into orbit.
Following the Mercury missions, the Gemini project made significant strides towards a successful Moon flight. The Gemini capsule was propelled by an even more power ICBM, the Titan, and allowed astronauts to remain in space for up to two weeks, during which astronauts had the first experience with space-walking, and rendezvous and docking procedures with the Gemini spacecraft. An incredible ten Gemini missions were flown throughout 1965-66. The high success rate of the missions was testament to the improving reliability of NASA’s rockets and spacecraft, and allowed NASA engineers to collect invaluable data for the coming Apollo Moon missions. The Titan missile itself, remains as one of the most successful and long-lived rockets (1959-2005), carrying the Viking spacecraft to Mars, the Voyager probe to the outer solar system, and multiple heavy satellites into orbit. At about the same time, around the early 1960s, an entire family of versatile rockets, the Delta family, was being developed. The Delta family became the workhorse of the US space programme achieving more than 300 launches with a reliability greater than 95% percent! The versatility of the Delta family was based on the ability to tailor the lifting capability, using different interchangeable stages and external boosters that could be added for heavier lifting.
At this point, the tide had mostly turned. The United States had been off to a slow start but had used the data from their early failures to improve the design and reliability of their rockets. The Soviets, while being more successful initially, could not achieve the same rate of launch success and this significantly hampered their efforts during the upcoming race to the moon.
The Delta 4 rocket family (Photo Credit: United Launch Alliance)
To get to the moon, a much more powerful rocket than the Titan or Delta rockets would be needed. This now infamous rocket, the 110.6 m (330 feet) tall Saturn V (check out this sick drawing), consisted of three separate main rocket stages; the Apollo capsule with a small fourth propulsion stage for the return trip; and a two-staged lunar lander, with one stage for descending onto the Moon’s surface and the other for lifting back off the Moon. The Saturn V was largely the brainchild and crowning achievement of Wernher von Braun, the original lead developer of the V-2 rocket in WWII Germany, with a capability of launching 140,000 kg (310,000 lb) into low-Earth orbit and 48,600 kg (107,100 lb) to the Moon. This launch capability dwarfed all previous rockets and to this day remains the tallest, heaviest and most powerful rocket ever built to operational flying status (last on the chart at the start of the piece). NASA’s efforts reached their glorious climax with the Apollo 11 mission on July 20, 1969 when astronaut Neil Armstrong became the first man to set foot on the Moon, a mere 11.5 years after the first successful launch of the Explorer I satellite. The Apollo 11 mission became the first of six successful Moon landings throughout the years 1969-1972. A smaller version of the moon rocket, the Saturn IB, was also developed and used for some of the early Apollo test missions and later to transport three crews to the US space station Skylab.
The Space Shuttle

The Space Shuttle Discovery
However, this goal is now on the agenda of commercial space companies such as SpaceX, Reaction Engines, Blue Origin, Rocket Lab and the Sierra Nevada Corporation.
New approaches
After the demise of the Space Shuttle programme in 2011, the US’ capability of launching humans into space was heavily restricted. NASA is currently working on a new Space Launch System (SLS), the aim of which is to extend NASA’s range beyond low-Earth orbit and further out into the Solar system. Although the SLS is being designed and assembled by NASA, other partners such as Boeing, United Launch Alliance, Orbital ATK and Aerojet Rocketdyne are co-developing individual components. The SLS specification as it stands would make it the most powerful rocket in history and the SLS is therefore being developed in two stages (reminiscent of the Saturn IB and Saturn V rocket). First, a rocket with a payload capability of 70 metric tons (175,000 lb) is being developed from components of previous rockets. The goal of this heritage SLS is to conduct two lunar flybys with the Orion spacecraft, one unmanned and the other with a crew. Second, a more advanced version of the SLS with a payload capability of 130 metric tons (290,000 lb) to low-earth orbit, about the same payload capacity and 20% more thrust than the Saturn V rocket, is deemed to carry scientific equipment, cargo and the manned Orion capsule into deep space. The first flight for an unmanned Orion capsule on a trip around the moon is planned for 2018, while manned missions are expected by 2021-2023. By 2026 NASA plans to send a manned Orion capsule to an asteroid previously placed into lunar orbit by a robotic “capture-and-place” mission.

NASA’s upgrade plan for the SLS

When will this become reality?
Blue Origin, the rocket company of Amazon founder Jeff Bezos, is taking a similar approach of vertical takeoff and landing to re-usability and lower launch costs. The company is on an incremental trajectory to extend its capabilities from suborbital to orbital flight, led by its motto “Gradatim Ferocity” (latin for step by step, ferociously). Blue Origin’s New Shepard rocket underwent its first test flight in April 2015. In November 2015 the rocket landed successfully after a suborbital flight to 100 km (330,000 ft) altitude and this was extended to 101 km (333,000 ft) in January 2016. Blue hopes to extend its capabilities to human spaceflight by 2018.
Reaction Engines is a British aerospace company conducting research into space propulsion systems focused on the Skylon reusable single-stage-to-orbit spaceplane. The Skylon would be powered by the SABRE engine, a rocket-based combined cycle, i.e. a combination of an air-breathing jet engine and a rocket engine, whereby both engines share the same flow path, reusable for about 200 flights. Reaction Engines believes that with this system the cost of carrying one kg (2.2 lb) of payload into low-earth orbit can be reduced from the $1,500 today (early 2016) to around $900. The hydrogen-fuelled Skylon is designed to take-off from a purpose built runway and accelerate to Mach 5 at 28.5 km (85,500 feet) altitude using the atmosphere’s oxygen as oxidiser. This air-breathing part of the SABRE engine works on the same principles as a jet engine. A turbo-compressor is used to raise the pressure ratio of the incoming atmospheric air, which is pre-staged by a pre-cooler to cool the hot air impinging on the engine at hypersonic speeds. The compressed air is fed into a rocket combustion chamber where it is ignited with liquid hydrogen. As in a standard jet engine, a high pressure ratio is crucial to pack as much of the oxidiser into the combustion chamber and increase the thrust of the engine. As the natural source of oxygen runs out at high altitude, the engines switch to the internally stored liquid oxygen supplies, transforming the engine into a closed-cycle rocket and propelling the Skylon spacecraft into orbit. The theoretical advantages of the SABRE engine is its high fuel efficiency and low mass, which facilitate the single-stage-to-orbit approach. Reminiscent of the Shuttle, after deploying the its payload of up to 15 tons (38,000 lb), the Skylon spacecraft would then re-enter the atmosphere protected by a heat shield and land on a runway. The first ground tests of the SABRE engine are planned for 2019 and first unmanned test flights are expected for 2025.

SABRE rocket engine
Sierra Nevada Corporation is working alongside NASA to develop the Dream Chaser spacecraft for transporting cargo and up to seven people to low-earth orbit. The Dream Chaser is designed to launch on top of the Atlas V rocket (in place of the nose cone) and land conventionally by gliding onto a runway. The Dream Chaser looks a lot like a smaller version of the Space Shuttle, so intuitively one would expect the same cost inefficiencies as for the Shuttle. However, the engineers at Sierra Nevada say that two changes have been made to the Dream Chaser that should reduce the maintenance costs. First, the thrusters used for attitude control are ethanol-based, and therefore not toxic and a lot less volatile than the hydrazine-based thursters used by the Shuttle. This should allow maintenance of the Dream Chaser to ensue immediately after landing and reduce the time between flights. Second, the thermal protection system is based on an ablative tile that can survive multiple flights and can be replaced in larger groups rather than tile-by-tile. The Dream Chaser is planned to undergo orbital test flights in November 2016.

The Dream Chaser
Where do we go from here?
As we have seen, over the last 2000 years rockets have evolved from simple toys and military weapons to complex machines capable of transporting humans into space. To date, rockets are the only viable gateway to places beyond Earth. Furthermore, we have seen that the development of rockets has not always followed a uni-directional path towards improvement. Our capability to send heavier and heavier payloads into space peaked with the development of the Saturn V rocket. This great technological leap was fuelled, to a large extent, by the competitive spirit of the Soviet Union and the United States. Unprecedented funds were available to rocket scientists on both sides during the 1950-1970s. Furthermore, dreamers and visionaries such as Jules Verne, Konstantin Tsiolkovsky and Gene Roddenberry sparked the imagination of the public and garnered support for the space programs. After the 2003 Columbia disaster, public support for spending taxpayer money on often over-budget programs understandably waned. However, the successes of incumbent companies, their fierce competition and visionary goals of colonising Mars are once again inspiring a younger generation. This is, once again, an exciting time for rocketry.
Sources
Tom Benson (2014). Brief History of Rockets. NASA URL: https://www.grc.nasa.gov/www/k-12/TRC/Rockets/history_of_rockets.html
NASA. A Pictorial History of Rockets. URL: https://www.nasa.gov/pdf/153410main_Rockets_History.pdf
John Partridge is the founder of the deap-sea instrumentation company Sonardyne, and also graduated from the University of Bristol, my alma mater, with a degree in Mechanical Engineering in 1962. Since the founding in 1971, Sonardyne has developed into one of the leading instrumentation companies in oceanography, oil drilling, underwater monitoring and tsunami warning systems.
During my PhD graduation ceremony last week John Partridge received an honorary doctorate in engineering for his contributions to the field. His acceptance speech was shorter than most but packed a punch. Among others, he discussed the current state of engineering progress, the three essential characteristics an engineer should possess and his interests in engineering education.
The last topic is one close to my heart and one of the reasons this blog exists at all. I have transcribed Dr Partridge’s speech and you can find the full copy here, or alternatively listen to the speech here. What follows are excerpts from his speech that I found particularly interesting with some additional commentary on my part. All credit is due to Dr Partridge and any errors in transcribing are my own.
Straight off the bat Dr Partridge reminds us of the key skills required in engineering, namely inventiveness, mathematical analysis and decision making:
Now I am going to get a bit serious about engineering education. According to John R. Dixon, a writer on engineering education, the key skills required in engineering are inventiveness, analysis and decision making. Very few people have all three of Dickson’s specified skills, which is why engineering is best done as a group activity, and it is why I am totally indebted to my engineering colleagues in Sonardyne, particularly in compensating for my poor skills at mathematical analysis. Some of my colleagues joined Sonardyne straight from university and stayed until their retirement. But the really difficult part of running a business is decision making, which applies at all stages and covers a wide variety of subjects: technical, commercial, financial, legal. One incorrect decision can spell the end of a substantial company. In recent decades, bad decisions by chief executives have killed off large successful British companies some of which had survived and prospered for over a century.
The key tenet of John R. Dixon’s teachings is that engineering design is essentially science-based problem solving with social human awareness. Hence, the character traits often attributed to successful engineering, for example intelligence, creativity and rationality (i.e. inventiveness and analysis), which are typically the focus of modern engineering degrees, are not sufficient in developing long-lasting engineering solutions. Rather, engineering education should focus on distilling a “well-roundedness”, in the American liberal arts sense of the word.
As Dr Partridge points out in his speech, this requires a basic understanding of decision making under uncertainty, as pioneered by Kahnemann and Tversky, and how to deal with randomness or mitigate the effects of Black Swan events (see Taleb). Second, Dr Partridge acknowledges that combining these characteristics in a single individual is difficult, if not impossible, such that companies are essential in developing good engineering solutions. This means that soft skills, such as team work and leadership, need to be developed simultaneously and a basic understanding of business (commercial, financial and legal) is required to operate as an effective and valuable member of an engineering company.
Next, Dr Partridge turns his attention to the current state of technology and engineering. He addresses the central question, has the progress of technology, since the development of the transistor, the moon landings and the wide-spread use of the jet engine, been quantitative or qualitative?
I remember a newspaper article by [Will] Hutton, [political economist and journalist, now principal of Hertford College, Oxford], decades ago entitled “The familiar shape of things to come”, a pun on H.G. Wells’ futuristic novel “The unfamiliar shape of things to come”. Hutton’s article explained how my parents’ generation, not my generation, not your generation, my parents’ generation had experienced the fastest rate of technological change in history. They grew up in the era of gas light but by the end of their days the man had been on the moon, jet airliners and colour television were a common experience. But, Hutton argued, since the 1960s subsequent progress of technology has been quantitative rather than qualitative.
But, how about the dramatic improvements in microelectronics and communications, etc.?, much of which has occurred since Hutton’s article was written. Are they quantitative or qualitative improvements? I think they are quantitative because so much of the groundwork had already been completed long before the basic inventions could be turned into economical production. […T]he scientific foundation for present microelectronic technology, way [laid] back in the 1930s. [This] work in solid state physics provided the underpinning theory that enabled the invention of the transistor in the 1950s. Now we harbour millions of these tiny devices inside the mobile phones of our pockets. That is quantitative progress from bytes to gigabytes.
This reminds me of one of Peter Thiel’s, co-founder of the Silicon Valley venture capital firm Founders Fund, statements “We wanted flying cars, instead we got 140 characters”. On the Founders Fund website the firm has published a manifesto “What happened to the future?”. In the aerospace sector alone, the manifesto addresses two interesting case studies, namely that the cost of sending 1kg of cargo into orbit has barely decreased since the Apollo program of the 1960’s (of course Elon Musk is on a mission to change this), and that, since the retirement of the Concorde, the time for crossing the Atlantic has actually gone up.
While I don’t fundamentally agree with Thiel’s overall assessment of the state of technology, I believe there is abundant evidence that the technologies around us are, to a large extent, more powerful, faster and generally improved versions of technology that already existed in the 1960s, hence quantitative improvements. On the other hand, the addition of incremental changes over long periods of time can lead to dramatic changes. The best example of this is Moore’s Law, i.e. the observation that the number of transistors on an integrated circuit chip doubles every 18 to 24 months.
At face value, this is clearly quantitative progress, but what about the new technologies that our new found computational power has facilitated? Without this increase in computational power, the finite element method would not have taken off in the 1950s and engineers would not be able to model complex structural and fluid dynamic phenomena today. Similarly, computers allow chemists to develop new materials specifically designed for a predefined purpose. Digital computation facilitated the widespread use of control theory, which is now branching into new fields such as 3D printing and self-assembly of materials at the nano-scale (both control problems applied to chemistry). Are these new fields not qualitative?
The pertinent philosophical questions seems to be, what qualifies as qualitative progress? As a guideline we can turn to Thomas Kuhn’s work on scientific revolutions. Kuhn challenged the notion of scientific progress on a continuum, i.e. by accumulation, and proposed a more discrete view of scientific progress by “scientific revolutions”. In Kuhn’s view the continuity of knowledge accumulation is interrupted by spontaneous periods of revolutionary science driven by anomalies, which subsequently lead to new ways of thinking and a roadmap for new research. Kuhn defined the characteristics of a scientific revolution as follows:
- It must resolve a generally accepted problem with the current paradigm that cannot be reconciled in any other way
- It must preserve, and hence agree with a large part of previously accrued scientific knowledge
- It must solve more problems, and hence open up more questions than its predecessor.
With regards to this definition I would say that nanotechnology, 3D printing and shape-adaptive materials, to name a few, are certainly revolutionary technologies in that they allow us to design and manufacture products that were completely unthinkable before. In fact I would argue that the quantitative accumulation of computation power has facilitated a revolution towards more optimised and multifunctional structures akin to the design we see in nature. To name another, more banal example, the modern state of manufacturing has been transformed through globalisation. 30 years ago products were most exclusively manufactured in one country and then consumed there. The reality today is that different factories in different countries manufacture small components which are then assembled in a central processing unit. This assembly process has two fundamental enablers, IT and the modern logistics system. This engineering progress is certainly revolutionary, but perhaps not as sexy as flying cars and therefore not as present in the media or our minds.
The problem that Dr Partridge sees is that the tradition of engineering philosophy is not as well developed as that of science.
So what is engineering? Is it just a branch of applied science, or does it have a separate nature? What is technology? These questions were asked by Gordon Rodgers in his 1983 essay “The nature of engineering and philosophy of technology”. […] The philosophy of science has a large corpus of work but the philosophy of technology is still an emerging subject, and very relevant to engineering education.
In this regard, I agree with David Blockley (who I have written about before) that engineering is too broad to be defined succinctly. In its most general sense it is the act of using technical and scientific knowledge to turn an idea, supporting a specific human endeavour, hence a tool, into reality. Of course the act of engineering involves all forms of art, science and craft through conception, design, analysis and manufacturing. As homo sapiens our ingenuity in designing tools played a large part in our anthropological development, and according to Winston Churchill “we shape our tools and thereafter they shape us”.
So perhaps another starting point in addressing the quantitative/qualitative dichotomy of engineering progress is to consider how much humans have changed as a result of recent technological inventions. Are the changes in human behaviour due to social media and information technology of a fundamental kind or rather of degree? In terms of aerospace engineering, the last revolution of this kind was indeed the commercialisation of jet travel, and until affordable space travel becomes a reality, I see no revolutions of this kind in the near past or future.
So it seems more inventiveness is crucial for further progress in the aerospace industry. As a final thought, Dr Partridge ends with an interesting question:
Can one teach inventiveness or is it a gift?
Let me know your thoughts in the comments.
One of the key factors in the Wright brothers’ achievement of building the first heavier-than-air aircraft was their insight that a functional airplane would require a mastery of three disciplines:
- Lift
- Propulsion
- Control
Whereas the first two had been studied to some success by earlier pioneers such as Sir George Cayley, Otto Lilienthal, Octave Chanute, Samuel Langley and others, the question of control seemed to have fallen by the wayside in the early days of aviation. Even though the Wright brothers build their own little wind tunnel to experiment with different airfoil shapes (mastering lift) and also built their own lightweight engine (improving propulsion) for the Wright flyer, a bigger innovation was the control system they installed on the aircraft.

The Wright Flyer: Wilbur makes a turn using wing-warping and the movable rudder, October 24, 1902. By Attributed to Wilbur Wright (1867–1912) and/or Orville Wright (1871–1948). [Public domain], via Wikimedia Commons.
- The longitudinal axis from nose to tail, also called the axis of roll, i.e. rolling one wing up and one wing down.
- The lateral axis from wing tip to wing tip, also called the axis of pitch, i.e. nose up or nose down.
- The normal axis from the top of the cabin to the bottom of landing gear, also called the axis of yaw, i.e. nose rotates left or right.

Aircraft Principal Axes (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
For example:
- Moving the elevator down increases the effective camber across the horizontal tail plane, thereby increasing the aerodynamic lift at the rear of the aircraft and causing a nose-downward moment about the aircraft’s centre of gravity. Alternatively, an upward movement of the elevator induces a nose-up movement.
- In the case of the rudder, deflecting the rudder to one side increases the lift in the opposite direction and hence rotates the aircraft nose in the direction of the rudder deflection.
- In the case of ailerons, one side is being depressed while the other is raised to produce increased lift on one side and decreased lift on the other, thereby rolling the aircraft.

Aircraft Control Surfaces By Piotr Jaworski (http://www.gnu.org/copyleft/fdl.html) via Wikimedia Commons
Today, many other control systems are being used in addition to, or instead of, the conventional system outlined above. Some of these are:
- Elevons – combined ailerons and elevators.
- Tailerons – two differentially moving tailplanes.
- Leading edge slats and trailing edge flaps – mostly for increased lift at takeoff and landing.
But ultimately the action of operation is fundamentally the same, the lift over a certain portion of the aircraft is changed, causing a moment about the centre of gravity.
Special Aileron Conditions
Two special conditions arise in the operation of the ailerons.
The first is known as adverse yaw. As the ailerons are deflected, one up and one down, the aileron pointing down induces more aerodynamic drag than the aileron pointing up. This induced drag is a function of the amount of lift created by the airfoil. In simplistic terms, an increase in lift causes more pronounced vortex shedding activity, and therefore a high-pressure area behind the wing, which acts as a net retarding force on the aircraft. As the downward pointing airfoil produces more lift, induced drag is correspondingly greater. This increased drag on the downward aileron (upward wing) yaws the aircraft towards this wing, which must be counterbalanced by the rudder. Aerodynamicists can counteract the adverse yawing effect by requiring that the downward pointing aileron deflects less than the upward pointing one. Alternatively, Frise ailerons are used, which employ ailerons with excessively rounded leading edges to increase the drag on the upward pointing aileron and thereby help to counteract the induced drag on the downward pointing aileron of the other wing. The problem with Frise ailerons is that they can lead to dangerous flutter vibrations, and therefore differential aileron movement is typically preferred.
The second effect is known as aileron reversal, which occurs under two different scenarios.
- At very low speeds with high angles of attack, e.g. during takeoff or landing, the downward deflection of an aileron can stall a wing, or at the least reduce the lift across the wing, by increasing the effective angle of attack past sustainable levels (boundary layer separation). In this case, the downward aileron produces the opposite of the intended effect.
- At very high airspeeds, the upward or downward deflection of an aileron may produce large torsional moments about the wing, such that the entire wing twists. For example, a downward aileron will twist the trailing edge up and leading edge down, thereby decreasing the angle of attack and consequently also the lift over that wing rather than increasing it. In this case, the structural designer needs to ensure that the torsional rigidity of the wing is sufficient to minimise deflections under the torsional loads, or that the speed at which this effect occurs is outside the design envelope of the aircraft.
Stability
What do we mean by the stability of an aircraft? Fundamentally we have to discern between the stability of the aircraft to external impetus, with and without the pilot responding to the perturbation. Here we will limit ourselves to the inherent stability of the aircraft. Hence the aircraft is said to be stable if it returns back to its original equilibrium state after a small perturbing displacement, without the pilot intervening. Thus, the aircraft’s response arises purely from the inherent design. At level flight we tend to refer to this as static stability. In effect the airplane is statically stable when it returns to the original steady flight condition after a small disturbance; statically unstable when it continues to move away from the original steady flight condition upon a disturbance; and neutrally stable when it remains steady in a new condition upon a disturbance. The second, and more pernicious type of stability is dynamic stability. The airplane may converge continuously back to the original steady flight state; it may overcorrect and then converge to the original configuration in a oscillatory manner; or it can diverge completely and behave uncontrollably, in which case the pilot is well-advised to intervene. Static instability naturally implies dynamic instability, but static stability does not generally guarantee dynamic stability.

Three cases for static stability: following a pitch disturbance, aircraft can be either unstable, neutral, or stable. By Olivier Cleynen via Wikimedia Commons.
By longitudinal stability we refer to the stability of the aircraft around the pitching axis. The characteristics of the aircraft in this respect are influenced by three factors:
- The position of the centre of gravity (CG). As a rule of thumb, the further forward (towards the nose) the CG, the more stable the aircraft with respect to pitching. However, far-forward CG positions make the aircraft difficult to control, and in fact the aircraft becomes increasingly nose heavy at lower airspeeds, e.g. during landing. The further back the CG is moved the less statically stable the aircraft becomes. There is a critical point at which the aircraft becomes neutrally stable and any further backwards movement of the CG leads to uncontrollable divergence during flight.
- The position of the centre of pressure (CP). The centre of pressure is the point at which the aerodynamic lift forces are assumed to act if discretised onto a single point. Thus, if the CP does not coincide with the CG, pitching moments will naturally be induced about the CG. The difficulty is that the CP is not static, but can move during flight depending on the angle of incidence of the wings.
- The design of the tailplane and particularly the elevator. As described previously, the role of the elevator is to control the pitching rotations of the aircraft. Thus, the elevator can be used to counter any undesirable pitching rotations. During the design of the tailplane and aircraft on a whole it is crucial that the engineers take advantage of the inherent passive restoring capabilities of the elevator. For example, assume that the angle of incidence of the wings increases (nose moves up) during flight as a result of a sudden gust, which gives rise to increased wing lift and a change in the position of the CP. Therefore, the aircraft experiences an incremental change in the pitching moment about the CG given by
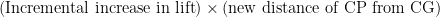
At the same time, the elevator angle of attack also increases due to the nose up/tail down perturbation. Hence, the designer has to make sure that the incremental lift of the elevator multiplied by its distance from the CG is greater than the effect of the wings, i.e.

As a result the interplay between CP and CG, tailplane design greatly influences the degree of static pitching stability of an aircraft. In general, due to the general tear-drop shape of an aircraft fuselage, the CP of an aircraft is typically ahead of it’s CG. Thus, the lift forces acting on the aircraft will always contribute some form of destabilising moment about the CG. It is mainly the job of the vertical tailplane (the fin) to provide directional stability, and without the fin most aircraft would be incredibly difficult to fly if not outright unstable.
Lateral Stability
By lateral stability we are referring to the stability of the aircraft when rolling one wing down/one wing up, and vice versa. As an aircraft rolls and the wings are no longer perpendicular to the direction of gravitational acceleration, the lift force, which acts perpendicular to the surface of the wings, is also no longer parallel with gravity. Hence, rolling an aircraft creates both a vertical lift component in the direction of gravity and a horizontal side load component, thereby causing the aircraft to sideslip. If these sideslip loads contribute towards returning the aircraft to its original configuration, then the aircraft is laterally stable. Two of the more popular methods of achieving this are:
- Upward-inclined wings, which take advantage of the dihedral effect. As an aircraft is disturbed laterally, the rolling action to one side results in a greater angle of incidence on the downward-facing wing than the upward-facing one. This occurs because the forward and downward motion of the wing is equivalent to a net increase in angle of attack, whereas the forward and upward motion of the other wing is equivalent to a net decrease. Therefore, the lift acting on the downward wing is greater than on the upward wing. This means that as the aircraft starts to roll sideways, the lateral difference in the two lift components produces a moment imbalance that tends to restore the aircraft back to its original configuration. This is in effect a passive controlling mechanism that does not need to be initiated by the pilot or any electronic stabilising control system onboard. The opposite destabilising effect can be produced by downward pointing anhedral wings, but conversely this design improves manoeuvrability.
The Dihedral Effect with Sideslip. Figure from (1).
- Swept back wings. As the aircraft sideslips, the downward-pointing wing has a shorter effective chord length in the direction of the airflow than the upward-pointing wing. The shorter chord length increases the effective camber (curvature) of the lower wing and therefore leads to more lift on the lower wing than on the upper. This results in the same restoring moment discussed for dihedral wings above.
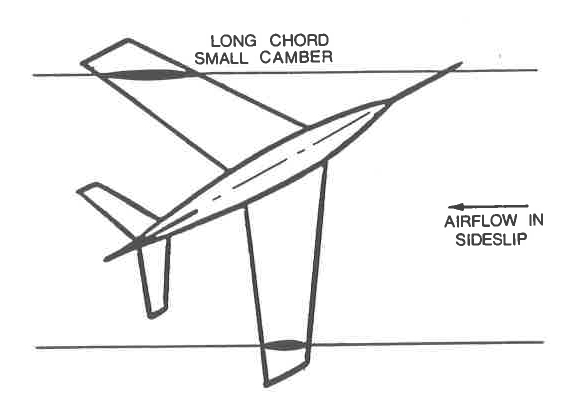
The Sweepback Effect of Shortened Chord. Figure from (1).
It is worth mentioning that the anhedral and backward wept wings can be combined to reach a compromise between stability and manoeuvrability. For example, an aircraft may be over-designed with heavily swept wings, with some of the stability then removed by an anhedral design to improve the manoeuvrability.

From Calvin and Hobbes Daily (http://calvinhobbesdaily.tumblr.com/image/137916137184)
Interaction of Longitudnal/Directional and Lateral Stability
As described above, movement of the aircraft in one plane is often coupled to movement in another. The yawing of an aircraft causes one wing to move forwards and the other backwards, and thus alters the relative velocities of the airflow over the wings, thereby resulting in differences in the lift produced by the two wings. The result is that yawing is coupled to rolling. These interaction and coupling effects can lead to secondary types of instability.
For example, in spiral instability the directional stability of yawing and lateral stability of rolling interact. When we discussed lateral stability, we noted that the sideslip induced by a rolling disturbance produces a restoring moment against rolling. However, due to directional stability it also produces a yawing effect that increases the bank. The relative magnitude of the lateral and directional restoring effects define what will happen in a given scenario. Most aircraft are designed with greater directional stability, and therefore a small disturbance in the rolling direction tends to lead to greater banking. If not counterbalanced by the pilot or electronic control system, the aircraft could enter an ever-increasing diving turn.
Another example is the dutch roll, an intricate back-and-forth between yawing and rolling. If a swept wing is perturbed by a yawing disturbance, the now slightly more forward-pointing wing generates more lift, exactly for the same argument as in the sideswipe case of shorter effective chord and larger effective area to the airflow. As a result, the aircraft rolls to the side of the slightly more backward-pointing wing. However, the same forward-pointing wing with higher lift also creates more induced drag, which tends to yaw the aircraft back in the opposite direction. Under the right circumstances this sequence of events can perpetuate to create an uncomfortable wobbling motion. In most aircrafts today, dampers in the automatic control system are installed to prevent this oscillatory instability.
In this post I have only described a small number of control challenges that engineers face when designing aircraft. Most aircraft today are controlled by highly sophisticated computer programmes that make loss of control or stability highly unlikely. Free unassisted “Flying-by-wire”, as it is called, is getting rarer and mostly limited to start and landing manoeuvres. In fact, it is more likely that the interface between human and machine is what will cause most system failures in the future.
References
(1) Richard Bowyer (1992). Aerodynamics for the Professional Pilot. Airlife Publishing Ltd., Shrewsbury, UK.
“We must ensure this never happens again.”
This is a common reaction to instances of catastrophic failure. However, in complex engineering systems, this statement is inherently paradoxical. If the right lessons are learned and the appropriate measures are taken, the same failure will most likely never happen again. But, catastrophes in themselves are not completely preventable, such that the next time around, failure will occur somewhere new and unforeseen. Welcome to the world of complexity.
Boiled down to its fundamentals, engineering deals with the practical – the development of tools that work as intended. Failure is a human condition, and as such, all man-made systems are prone to failure. Furthermore, success should not be defined as the absence of failure, but rather how we cope with failure and learn from it – how we conduct ourselves in spite of failure.
Failure and risk are closely linked. The way I define risk here is the probability of an irreversible negative outcome. In a perfect world of complete knowledge and no risk, we know exactly how a system will behave beforehand and have perfect control of all outcomes. Hence, in such an idealised world there is very little room for failure. In the real world however, knowledge is far from complete, people and man-made systems behave and interact in unforeseen ways, and changes in the surrounding environmental conditions can drastically alter the intended behaviour. Therefore, our understanding of and attitude towards risk, plays a major role in building safe engineering systems.
The first step is to acknowledge that our perception of risk is very personal. It is largely driven by human psychology and depends on a favourable balance of risk and reward. For example, there is a considerable higher degree of fear of flying than fear of driving, even though air travel is much safer than road travel. As plane crashes are typically more severe than car crashes, it is easy to form skewed perceptions of the respective risks involved. What is more, driving a car, for most people a daily activity, is far more familiar than flying an airplane.
Second, science and engineering do not attempt to predict or guarantee a certain future. There will never be a completely stable, risk free system. All we can hope to achieve is a level of risk that is comparable to that of events beyond our control. Risk and uncertainty arise in the gap between what we know and what we don’t – between how we design the system to behave and how it can potentially behave. This knowledge gap can lead to two types of risk. There are certain things we appreciate that we do not understand, i.e. the known unknowns. Second, and more pernicious, are those things we are not even aware of, i.e. the unknown unknowns, and it is these failures that wreak the most havoc. So how do we protect ourselves against something we don’t even see coming? How do engineers deal with this second type of risk?
The first strategy is the safety factor or margin of safety. A safety factor of 2 means that if a bridge is expected to take a maximum service load of X (also called the demand), then we design the structure to hold 2X (also called the capacity). In the aerospace industry, safety protocols require all parts to maintain integrity up to 1.2x the service load, i.e. a limit safety factor of 1.2. Furthermore, components need to sustain 1.5x the service load for at least three seconds, the so-called ultimate safety factor. In some cases, statistical techniques such as Monte Carlo analyses are used to calculate the probability that the demand will exceed the capacity.
The second strategy is to employ redundancies in the design. Hence, back-ups or contingencies are in place to prevent a failure from progressing to catastrophic levels. In structural design, for example, this means that there is enough untapped capacity within the structure, such that a local failure leads to a rebalancing/redirection of internal loads without inducing catastrophic failure. Part of this analysis includes the use of event and fault trees that require engineers to conjure the myriad of ways in which a system may fail, assign probabilities to these events, and then try to ascertain how a particular failure affects other parts of the system.

Even tree diagram (via Wikimedia Commons).
The increasing complexity in engineering systems is driven largely by the advance of technology based on our scientific understanding of physical phenomena at increasingly smaller length scales. For example, as you are reading this on your computer or smartphone screen, you are, in fact, interacting with a complex system that spans many different layers. In very crude terms, your internet browser sits on top of an operating system, which is programmed in one or many different programming languages, and these languages have to be translated to machine code to interact with the microprocessor. In turn, the computer’s processor interacts with other parts of the hardware such as the keyboard, mouse, disc drives, power supply, etc. which have to interface seamlessly for you to be able to make sense of what appears on screen. Next, the computer’s microprocessor is made up of a number of integrated circuits, which are comprised of registers and memory cells, which are further built-up from a network of logic gates, which ultimately, are nothing but a layer of interconnected semiconductors. Today, the expertise required to handle the details at a specific level is so vast, that very few people understand how the system works at all levels.
In the world of aviation, the Wright brothers were the first to realise that no one would ever design an effective aircraft without an understanding of the fields of propulsion, lift and control. Not only did they understand the physics behind flight, Orville and Wilbur were master craftsmen from years of running their own bike shop, and later went as far as building the engine for the Wright Flyer themselves. Today’s airplanes are of course significantly more sophisticated than the aircraft 100 years ago, such that in-depth knowledge of every aspect of a modern jumbo jet is out of the question. Yet, the risk of increasing specialism is that there are fewer people that understand the complete picture, and appreciate the complex interactions that can emerge from even simple, yet highly interconnected processes.
With increasing complexity, the solution should not be further specialisation and siloing of information, as this increases the potential for unknown risks. For example, consider the relatively simple case of a double pendulum. Such a system is described by chaotic behaviour, that is, we know and understand the underlying physics of the problem, yet it is impossible to predict how the pendulum will swing a priori. This is because at specific points, the system can bifurcate into a number of different paths, and the exact behaviour depends on the nature of the initial conditions when the system is started. These bifurcations can be very sensitive to small differences in the initial conditions, such that two processes that start with almost the same, but not identical, initial conditions can diverge considerably after only a short time.

A double rod pendulum animation showing chaotic behaviour (via Wikimedia Commons).
In this realm, engineers can learn from some of the strategies employed in medicine. Oftentimes, the origin, nature and cure of a disease is not clear beforehand, as the human body is its own example of a complex system with interacting levels of cells, proteins, molecules, etc. Some known cures work even though we do not understand the underlying mechanism, and some cures are not effective even though we understand the underlying mechanism. Thus, the engineering design process shifts from well-defined rules of best practise (know first then act) to emergent (act first then know), i.e. a system is designed to the best of current knowledge and then continuously iterated/refined based on reactions to failure.
In this world, the role of effective feedback systems is critical, as flaws in the design can remain dormant for many years and emerge suddenly when the right set of external circumstances arise. As an example, David Blockley provides an interesting analogy of how failures incubate in his book “Engineering: A very short introduction.”
“…[Imagine] an inflated balloon where the pressure of the air in the balloon represents the ‘proneness to failure’ of a system. … [W]hen air is first blown into the balloon…the first preconditions for [an] accident are established. The balloon grows in size and so does the ‘proneness to failure’ as unfortunate events…accumulate. If [these] are noticed, then the size of the balloon can be reduced by letting air out – in other words, [we] reduce some of the predisposing events and reduce the ‘proneness to failure’. However, if they go unnoticed…, then the pressure of events builds up until the balloon is very stretched indeed. At this point, only a small trigger event, such as a pin or lighted match, is needed to release the energy pent up in the system.”
Often, this final trigger is blamed as the cause of the accident. But it isn’t. If we prick the balloon before blowing it up, it will subsequently leak and not burst. The over-stretched balloon itself is the reason why an accident can happen in the first place. Thus, in order to reduce the likelihood of failure, the accumulation of preconditions has to be monitored closely, and necessary actions proposed to manage the problem.
The main challenge for engineers in the 21st century is not more specialisation, but the integration of design teams from multiple levels to facilitate multi-disciplinary thinking across different functional boundaries. Perhaps, the most important lesson is that it will never be possible to ensure that failures do not occur. We cannot completely eliminate risk, but we can learn valuable lessons from failures and continuously improve engineering systems and design processes to ensure that the risks are acceptable.
References
David Blockley (2012). Engineering: A very short introduction. Oxford University Press. Oxford, UK.
“Outsourcing” is a loaded term. In today’s globalised world it has become to mean many things – from using technology to outsource rote work over the internet to sharing capacity with external partners that are more specialised to complete a certain task. However, inherent in the idea of outsourcing is the promise of reduced costs, either through reductions in labour costs, or via savings in overheads and tied-up capital.
I recently stumbled across a 2001 paper [1] by Dr Hart-Smith of the Boeing Company, discussing some of the dangers and fallacies in our thinking regarding the potential advantages of outsourcing. The points raised by Hart-Smith are particularly noteworthy as they deal with the fundamental goals of running a business rather than trying to argue by analogy, or blind faith on proxy measurements. What follows is my take on the issue of outsourcing as it pertains to the aerospace industry only, loosely based on the insights provided by Dr Hart-Smith, and with some of my own understanding of the topic from disparate sources that I believe are pertinent to the discussion.
That being said, the circumstances under which outsourcing makes economical sense depends on a broad spectrum of variables and is therefore highly complex. If you feel that my thinking is misconstrued in any way, please feel free to get in touch. With that being said let’s delve a bit deeper into the good, the bad and the ugly of the outsourcing world.
Any discussion on outsourcing can, in my opinion, be boiled down to two fundamental drivers:
- The primary goal of running a business: making money. Taking non-profits aside, a business exists to make a profit for its shareholders. If a business doesn’t make any money today, or isn’t expected to make a profit in the future, i.e. is not valuable on a net present value basis, then it is a lousy business. Any other metric that is used to measure the performance of a business, be it efficiency ratios such as return on capital employed, are helpful proxies but not the ultimate goal.
- Outsourcing is based on Ricardo’s idea of comparative advantage, that is, if two parties decide to specialise in the production of two different goods and decide to trade, both parties are better off than if they produced both goods for autarchic use only, even if one party is more efficient than the other at producing both goods at the same time.
Using these two points as our guidelines it becomes clear very quickly under what conditions a company should decide to outsource a certain part of its business:
- Another company is more specialised in this line of business and can therefore create a higher-quality product. This can either be achieved via:
- Better manufacturing facilities, i.e. more precisely dimensioned components that save money in the final assembly process
- Superior technical expertise. A good example are the jet engines on an aircraft. Neither Boeing nor Airbus design or manufacture their own engines as the complexity of this particular product means that other companies have specialised to make a great product in this arena.
- The rare occasion that outsourcing a particular component of an aircraft results in a net overall profit for the entire design and manufacturing project. However, the decision to outsource should never be based on the notion of reduced costs for a single component, as there is no one-to-one causation between reducing costs for a single component and increased profits for the whole project.
Note, that in either case the focus is on receiving extra value for something the company pays for rather than on reducing costs. In fact, as I will explain below, outsourcing often leads to increases in cost, rather than cost reductions. Under these circumstances, it only makes sense to outsource if this additional cost is traded for extra value that cannot be created in house, i.e. manufacturing value or technical value.
Reducing Costs
Reducing costs is another buzzword that is often used to argue pro outsourcing. Considering the apparent first-order effects, it makes intuitive sense that offloading a certain segment of a business to a third party will reduce costs via lower labour costs and overheads, depreciation and capital outlays. In fact, this is one of the allures of the globalised world and the internet; the means of outsourcing work to lower-wage countries are cheaper than ever before in history.
However, the second-order effects of outsourcing are rarely considered. The first fundamental rule of ecology is that in a complex system you can never only do one thing. As all parts of a complex system are intricately linked, perturbing the system in one area will have inevitable knock-on effects in another area. Additionally if the system behaves non-linearly to the external stimuli, these knock-on effects are non-intuitive and almost impossible to predict a priori. Outsourcing an entire segment of a project should probably be classed as a major perturbation, and as all components of a complex engineering product, such as an aircraft, are inherently linked, a decision in one area will certainly effect other areas of the project as well. Hence, consider the following second-order effects that should be accounted for as a result of outsourcing as certain line of a business:
- Quality assurance is harder out-of-house, and hence reworking components that are not to spec may cost more in the long run.
- Additional labour may be required in-house in order to coordinate the outsourced work, interact with the third party and interface the outsourced component with the in-house assembly team.
- Concurrent engineering and the ability to adapt designs is much harder. In order to reduce their costs, subcontractors often operate on fixed contracts, i.e. the design specification for a component is fixed or the part to be manufactured can not be changed. Hence, the flexibility to adapt the design of a part further down the line is constricted, and this constraint may create a bottleneck for other interfacing components.
- Costs associated with subassemblies that cannot be fitted together balloon quickly, and the ensuing rework and detective work to find the source of the imprecision delays the project.
- There is a need for additional transportation due to off-site production and increased manufacturing time.
- It is harder to coordinate the manufacturing schedules of multiple external subcontractors who might all be employing different planning systems, and more inventory is usually created.
Therefore there is an inherent clash between trying to minimise costs locally, i.e. the costs for one component in isolation, and keeping costs down globally, i.e. for the entire project. In the domain of complex systems, local optimisation can lead to fragility of the system in two ways. First, small perturbations from local optima typically have greater effects on the overall performance of the system than perturbations from locally sub-optimal states. Second, locally optimising one factor of the system may force other factors to be far from their optima, and hence reduce the overall performance of the system. A general heuristic is that the best solution is to reach a compromise by operating individual components at sub-optimal levels, i.e. with excess capacity, such that the overall system is robust to adapt to unforeseen perturbations in its operating state.
Furthermore, the decision to outsource the design or the manufacture of a specific component needs to factored into the overall design of the product as a early as possible. Thus, all interfacing assemblies and sub-assemblies are designed with this particular reality in mind, rather than having to adapt to this situation a posteriori. This is because early design decisions have the highest impact on the final cost of a product. As a general rule of thumb, 80% of the final costs are incurred by the first 20% of the design decisions made, such that late design changes are always exponentially more expensive than earlier ones. Having to fix misaligned sub-assemblies at final assembly costs orders of magnitude more than additional planning up front.
Finally, the theory of constraints teaches us that the performance of the overall project can never exceed that of its least proficient component. Hence, the overall quality of the final assembly is driven by the quality of its worst suppliers. This means that in order to minimise any problems, the outsourcing company needs to provide extra quality and technical support for the subcontractors, extra employees for supply chain management, and additional in-house personal to deal with the extra detail design work and project management. Dr Hart-Smith warns that
With all this extra work the reality is that outsourcing should be considered as an extra cost rather than a cost saving, albeit, if done correctly, for the exchange of higher quality parts. The dollar value of out-sourced work is a very poor surrogate for internal cost savings.
Outsourcing Profits
Hypothetically, in the extreme case when every bit of design and manufacturing work is outsourced the only remaining role f0r the original equipment manufacturer (OEM) of the aircraft is to serve as a systems integrator. However, in this scenario, all profits are outsourced as well. This reality is illustrated by a simple example. The engines and avionics comprise about 50% of the total cost of construction of an aircraft, and the remaining 50% are at the OEM’s discretion. Would you rather earn a 25% profit margin on 5% of the total work, or rather 5% profit margin on 25% of the total work? In the former case the OEM will look much more profitable on paper (higher margin) but the total amount of cash earned in the second scenario will be higher. Hence, in a world where 50% of the work naturally flows to subcontractors supplying the engines, avionics and control systems, there isn’t much left of the aircraft to outsource if enough cash is to be made to keep the company in business. Without cash there is no money to pay engineers to design new aircraft and no cash on hand to serve as a temporary buffer in a downturn. If there is anything that the 20th century has taught us, is that in the world of high-tech, any company that does not innovate and purely relies on derivative products is doomed to be disrupted by a new player.
Second, subcontractors are under exactly the same pressure as the OEM to maximise their profits. In fact, subcontractors have a greater incentive for fatter margins and higher returns on investment as their smaller size increases their interest rates for loaned capital. This means that suppliers are not necessarily incentivised to manufacture tooling that can be reused for future products as these require more design time and can not be billed against future products. In-house production is much more likely to lead to this type of engineering foresight. Consider the production of a part that is estimated to cost the same to produce in-house as by a subcontractor, and to the same quality standards. The higher profit margins of the subcontractor naturally result in a higher overall price for the component than if manufactured in-house. However, standard accounting procedures would consider this as a cost reduction since all first-order costs, such as lower labour rate at the subcontractor, fewer employees and less capital tied up in hard assets at the OEM, creates the illusion that outside work is cheaper than in-house work.
Skin in the Game
One of the heavily outsourced planes in aerospace history was the Douglas Aircraft Company DC-10, and it was the suppliers who made all the profits on this plane. It is instrumental that most subcontractors were not willing to be classified as risk-sharing partners. In fact, if the contracts have been negotiated properly, then most subcontractors have very little downside risk. For financial reasons, the systems integrator can rarely allow a subcontractor to fail, and therefore provides free technical support to the subcontractor in case of technical problems. In extreme cases, the OEM is even likely to buy if subcontractor outright.
This state of little downside risk is what NN Taleb calls the absence of “skin in the game” [2]. Subcontractors typically do not behave like employees do. Employees or “risk-sharing” partners have a reputation to protect and fear the economic repercussions of losing their paychecks. On the one hand, employees are more expensive than contractors and limit workforce flexibility. On the other hand, employees guarantee a certain dependability and reliability for solid work, i.e. downside protection to shoddy work. In Taleb’s words,
So employees exist because they have significant skin in the game – and the risk is shared with them, enough risk for it to be a deterrent and a penalty for acts of undependability, such as failing to show up on time. You are buying dependability.
Subcontractors on the other hand typically have more freedom than employees. They fear the law more than being fired. Financial repercussions can be built into contracts, and bad performances may lead to loss in reputation, but an employee, by being part of the organisation and giving up some of his freedom, will always have more risk, and therefore behave in more dependable ways. There are examples, like Toyota’s ecosystem of subcontractors, where mutual trust and “skin in the game” is built into the network via well thought-out profit sharing, risk sharing and financial penalties, but these relationships are not ad hoc and are based on long-term relationships.
With a whole network of subcontractors the performance of an operation is limited by the worst-performing segment. In this environment, OEMs are often forced to assist bad-performing suppliers and therefore forced to accept additional costs. Again from NN Taleb [2],
If you miss on a step in a process, often the entire business shuts down – which explains why today, in a supposedly more efficient world with lower inventories and more subcontractors, things appear to run smoothly and efficiently, but errors are costlier and delays are considerably longer than in the past. One single delay in the chain can stop the entire process.
The crux of the problem is that a systems integrator, who is the one that actually sells the final product, i.e. gets paid last and carries the most tail risk, can only raise the price to levels that the market will sustain. Subcontractors, on the other hand, can push for higher margins and lock in a profit before the final plane is sold and thereby limit their exposure to cost over-runs.
ROE
The return on net assets or return on equity (ROE) metric is a very powerful proxy to measuring how efficiently a company uses its equity or net assets (assets – liabilities; where assets are everything the company owns and liabilities include everything the company owes) to create profit,

The difference between high-ROE and low-ROE businesses is illustrated here using a mining company and a software company as (oversimplified) examples. The mining company needs a lot of physical hard assets to dig metals out of the ground, and hence ties up considerable amount of capital in its operations. A software company on the other hand is asset-light as the cost of computing hardware has exponentially fallen in line with Morse Law. Thus, if both companies make the same amount of profit, then the software company will have achieved this more efficiently than the mining company, i.e. required less initial capital to create the same amount of earnings. The ROE is a useful metric for investors, as it provides information regarding the expected rate of return on their investment. Indeed, in the long run, the rate of return on an investment in a company will converge to the ROE.
In order to secure funding from investors and achieve favourable borrowing rates from lenders, a company is therefore incentivised to beef up its ROE. This can either be done by reducing the denominator of the ratio, or by increasing the numerator. Reducing equity either means running a more asset-light business or by increasing liabilities via the form of debt. This is why debt is also a form of leverage as it allows a company to earn money on outside capital. Increasing the numerator is simple on paper but harder in reality; increasing earnings without adding capacity, e.g. by cost reductions or price increases.
Therefore ROE is a helpful performance metric for management and investors but it is not the ultimate goal. The goal of a for-profit company is to make money, i.e. maximise the earnings power. Would you rather own a company that earns 20% on a business with $100 of equity or 5% on company with $1000 of tied up capital? Yes, the first company is more efficient at turning over a profit but that profit is considerably smaller than for the second company. Of course, if the first company has the chance to grow to the size of the second in a few years time, and maintains or even expands its ROE, then this is a completely different scenario and it would be a good investment to forego some earnings now for higher cashflow in the future. However, by and large, this is not the situation for large aircraft manufacturers such as Boeing and Airbus, and restricted to fast-growing companies in the startup world.
Second, it is foolish to assume that the numerator and denominator are completely decoupled. In fact, in a manufacturing-intense industry such as aerospace, the two terms are closely linked and their behaviour is complex, i.e. their are too many cause-and-effect relationships for us to truly understand how a reduction in assets will effect earnings. Blindly reducing assets, without taking into account its effect on the rate and cost of production, can always be considered as a positive effect as it always increase ROE. In this manner, ROE can be misused as a false excuse for excessive outsourcing. Given the complex relationship in the aerospace industry between earnings and net assets, the real value of the ROE ratio is to provide a ballpark figure of how much extra money the company can earn in its present state with a source of incremental capital. Thus, if a company with multiple billions in revenue currently has an ROE of 20%, than it can expect to earn an extra 20% if it employs an incremental amount of further capital in the business, where the exact incremental amount is of course privy to interpretation.
In summary, there is no guarantee that a reduction in assets will directly result in an increase in profits, and the ROE metric is easily misused to justify capital reductions and outsourcing, when in fact, it should be used as a ballpark figure to judge how much additional money can currently be made with more capital spending. Thus, ROE should only be used as a performance metric but never as the overall goal of the company.
A cautionary word on efficiency
In a similar manner to ROE, the headcount of a company is an indicator of efficiency. If the same amount of work can be done by fewer people, then the company is naturally operating more efficiently and hence should be more profitable. This is true to an extent but not in the limit. Most engineers will agree that in a perfect world, perfect efficiency is unattainable as a result of dissipating mechanisms (e.g. heat, friction, etc.). Hence, perfect efficiency can only be achieved when no work is done. By analogy, it is meaningless to chase ever-improving levels of efficiency if this comes at the cost of reduced sales. Therefore, in some instances it may be wise to employ extra labour capacity in non-core activities in order to maintain a highly skilled workforce that is able to react quickly to opportunities in the market place, even if this comes at the cost of reduced efficiency.
So when is outsourcing a good idea?
Outsourcing happens all over the world today. So there is obviously a lot of merit to the idea. However, as I have described above, decisions to outsource should not be made blindly on terms of shedding assets or reducing costs, and need to factored into the design process as early as possible. Outsourcing is a valuable tool in two circumstances:
- Access to better IP = Better engineering design
- Access to better facilities = More precise manufacturing
First, certain components on modern aircraft have become so complex in their own right that it is not economical to design and manufacture these parts in-house. As a result, the whole operation is outsourced to a supplier that specialises in this particular product segment, and can deliver higher quality products than the prime manufacturer. The best example of this are jet engines, which today are built by companies like Rolls-Royce, General Electric and Pratt & Whitney, rather than Airbus and Boeing themselves.
Second, contrary to popular belief, the major benefit of automation in manufacturing is not the elimination of jobs, but an increase in precision. Precision manufacturing prevents the incredibly costly duplication of work on out-of-tolerance parts further downstream in a manufacturing operation. Toyota, for example, understood very early on that in a low-cost operation, getting things right the first time around is key, and therefore anyone on the manufacturing floor has the authority to stop production and sort out problems as they arise. Therefore, access to automated precision facilities is crucial for aircraft manufacturers. However, for certain parts, a prime manufacturer may not be able to justify the high capital outlay for these machines as there is not enough capacity in-house for them to be utilised economically. Under these circumstances, it makes sense to outsource the work to an external company that can pool the work from a number of companies on their machines. This only makes sense if the supplier has sufficient capacity on its machines or is able to provide improved dimensional control, e.g. by providing design for assembly services to make the final product easier to assemble.
Conclusion
After this rather long exposition of the dangers of outsourcing in the aerospace industry, here are some of the key takeaways:
- Outsourcing should not be employed as a tool for cost reduction. More likely than not it will lead to extra labour and higher costs via increased transportation, rework and inventories for the prime manufacturer, and therefore this extra price should be compensated by better design engineering or better manufacturing precision than could be achieved in-house.
- Efficiency is not the primary goal of the operation, but can be used as a useful metric of performance. The goal of the operation is to make money.
- A basic level of work has to be retained in-house in order to generate sufficient cash to fund new products and maintain a highly skilled workforce. If the latter requires extra capacity, a diversification to non-core activities may be a better option than reducing headcount.
- Scale matters. Cost saving techniques for standardised high-volume production are typically inappropriate for low-volume industries like aerospace.
- Recognise the power of incentives. In-house employees typically have more “skin in the game” as risk-sharing partners ,and therefore produce more dependable work than contractors.
Sources
[1] L.J. Hart-Smith. Out-sourced profits – the cornerstone of successful subcontracting. Boeing paper MDC 00K0096. Presented at Boeing Third Annual Technical Excellence (TATE) Symposium, St. Louis, Missouri, 2001.
[2] N.N. Taleb. How to legally own another person. Skin in the Game. pp. 10-15. https://dl.dropboxusercontent.com/u/50282823/employee.pdf
How airplanes fly is one of the most fundamental questions in aerospace engineering. Given its importance to flight, it is surprising how many different and oftentimes wrong explanations are being perpetuated online and in textbooks. Just throughout my time in school and university, I have been confronted with several different explanations of how wings create lift.
Most importantly, the equal transit time theory, explained further below, is taught in many school textbooks and therefore instils faulty intuitions about lift very early on. This is not necessarily because more advanced theories are harder to understand or require a lot maths. In fact, the theory that requires the simplest assumptions and least abstraction is typically considered to be the most useful.
In science, the simplicity of a theory is a hallmark of its elegance. According to Einstein (or Louis Zukofsky or Roger Sessions or William of Ockham…I give up, who knows), “everything should be made as simple as possible, but not simpler.” Hence, the strength of a theory is related to:
- The simplicity of its assumptions, ideally as few as possible.
- The diversity of phenomena the theory can explain, including phenomena that other theories could not explain.
Keeping this definition in mind, let’s investigate some popular theories about how aircraft create lift.
The first explanation of lift that I came across as a middle school student was the theory of “Equal Transit Times”. This theory assumes that the individual packets of air flowing across the top and bottom surfaces must reach the trailing edge of the airfoil at the same time. For this to occur, the airflow over the longer top surface must be travelling faster than the air flowing over the bottom surface. Bernoulli’s principle, i.e. along a streamline an increasing pressure gradient causes the flow speed to decrease and vice versa, is then invoked to deduce that the speed differential creates a pressure differential between the top and bottom surfaces, which invariably pushes the wing up. This explanation has a number of fallacies:
- There is no physical law that requires equal transit times, i.e. the underlying assumptions are certainly not as simple as possible.
- It fails to explain why aircraft can fly upside down, i.e. does not explain all phenomena.
As this video shows, the air over the top surface does indeed flow faster than on the bottom surface, but the flows certainly do not reach the trailing edge at the same time. Hence, this theory of equal transit times is often referred to as the “Equal Transit Time Fallacy”.
In order to generalise the above theory, while maintaining the mathematical relationship between speed and pressure given by Bernoulli’s principle, we can relax the initial assumption of equal transit time. If we start from a phenomenological observation of streamlines around an airfoil, as depicted schematically below, we see can see that the streamlines are bunched together towards the top surface of the leading edge, and spread apart towards the bottom surface of the leading edge. The flow between two adjacent streamlines is often called a streamtube, and the upper and lower streamtubes are highlighted in shades of blue in the figure below. The definition of a streamline is the line a fluid particle would traverse as it flows through space, and thus, by definition, fluid can never cross a streamline. As two adjacent streamlines form the boundaries of the streamtubes, the mass flow rate through each streamtube must be conserved, i.e. no fluid enters from the outside, and no fluid particles are created or destroyed. To conserve the mass flow rate in the upper streamline as it becomes narrower, the fluid must flow faster. Similarly, to conserve the mass flow rate in the lower streamtube as it widens, the fluid must slow down. Hence, in accordance with the speed-pressure relationship of Bernoulli’s principle, this constriction of the streamtubes means that we have a net pressure differential that generates a lift force.

Flow lines around a NACA 0012 airfoil at 11° angle of attack, with upper and lower streamtubes identified.
Of course, this theory does not explain why the upper streamtube contracts and the lower streamtube expands in the first place. An intuitive explanation for this involves the argument that the angle of attack obstructs the flow more towards the bottom of the airfoil than towards the top. However, this does not explain how asymmetric airfoils with pronounced positive camber at zero angle of attack, as shown in the figure below, create lift. In fact, such profiles were successfully used on early aircraft due to their resemblance to bird wings. Again, this theory does not explain all the physical phenomena we would like it to explain, and is therefore not the rigorous theory we are looking for.

Asymmetric airfoil with pronounced camber [1]
Indeed, we can imagine a flow around a 2D cylinder shown in the figure below. The flow is symmetric from left-to-right and top-to-bottom and experiences no lift. If we now start the cylinder spinning at the rate 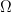
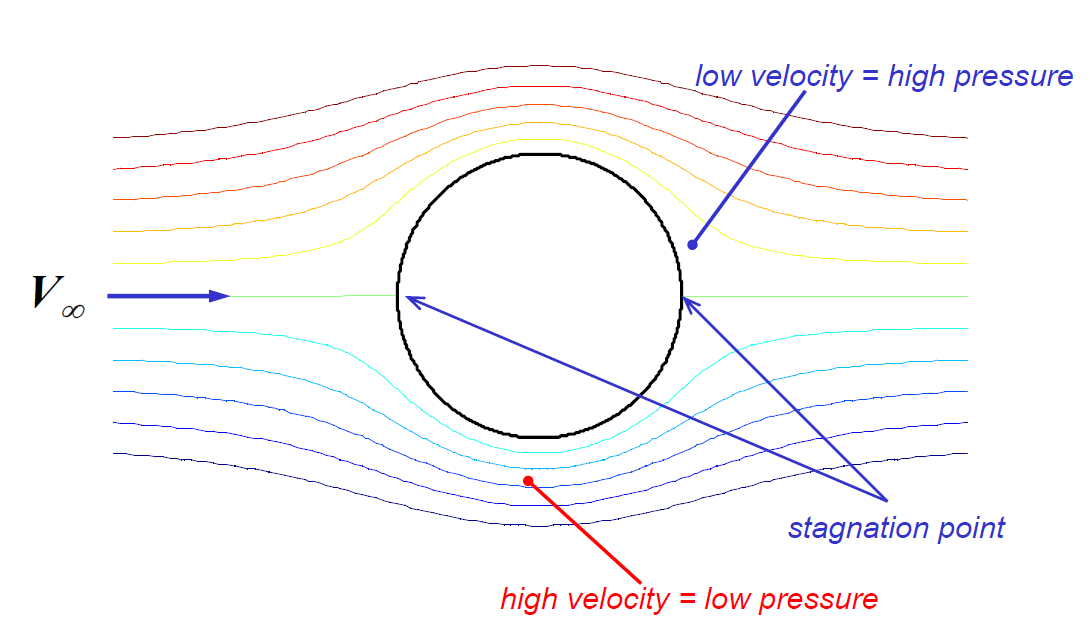
Flow around a cylinder
Flow around a rotating cylinder that induces lift
In the example above, lift was induced by creating an asymmetry in the curvature of the streamlines. In the stationary cylinder we had streamlines curving in one direction on the top surface, and by the same amount in the opposite direction on the bottom surface. Rotating the cylinder created an asymmetry in streamline curvature between the top and bottom surfaces (more curvature upwards then curvature downwards). We can create a similar asymmetry in the flow with a stationary cylinder by placing a small sharp-edged flap at the rear edge and positioned slightly downwards. Real viscous flow might not necessarily flow as smoothly around the little flap as shown in the diagram below, but this mental model is a neat tool to imagine how we can morphologically transition from a rotating cylinder that produces lift to an airfoil. This is shown via the series of diagrams below. This series of pictures shows that an airfoil creates a smoother variation in velocity than the cylinder, which leads to a smaller chance of boundary layer separation (a source of drag and in the worst-case scenario aerodynamic stall). A similar streamline profile could also be created with a symmetric airfoil that introduces asymmetry into the flow by being positioned at a positive angle of attack.
![]()
![]()
![]()
![]()
The reason why differences in streamline curvature induce lift is addressed in a journal paper by Dr Holger Babinsky, which is free to download. If we consider purely stead-state flow and neglect the effects of gravity, surface tension and friction we can derive some very basic, yet insightful, equations that explain the induced pressure difference. Quite intuitively this argument shows that a force acting parallel to a streamline causes the flow to accelerate or decelerate along its tangential path, whereas a force acting perpendicular to the flow direction causes the streamline to curve.
The first case is described mathematically by Bernoulli’s principle and depicted in the figure below. If we imagine a small fluid particle of finite length l situated in a field of varying pressure, then the front and back surfaces of the particle will experience different pressures. Say the pressure increases along the streamline, then the force acting on the front face pointing in the direction of motion is greater than the force acting on the rear surface. Hence, according to Newton’s second law, this increasing pressure field along the streamline causes the flow speed to decrease and vice versa. However, this approach is valid only along a single streamline. Bernoulli’s principle can not be used to relate the speed and pressures of adjacent streamlines. Thus, we can not use Bernoulli’s principle to compare the flows on the bottom and top surfaces of an airfoil, and therefore can say little about their relative pressures and speeds.
![Flow along a straight streamline [2]](https://aerospaceengineeringblog.com/wp-content/uploads/2015/10/Untitled.jpg)
Flow along a straight streamline [2]
![Flow along a curved streamline [2]](https://aerospaceengineeringblog.com/wp-content/uploads/2015/10/Untitled1.jpg)
Flow along a curved streamline [2]

where R is the radius of curvature of the flow and 
One positive characteristic of this theory is that it explains other phenomena outside our interest in airfoils. Vortices, such as tornados, consist of concentric circles of streamlines, which suggests that the pressure decreases as we move from the outside to the core of the vortex. This observation agrees with our intuitive understanding of tornados sucking objects into the sky.
With this understanding we can now return to the study of airfoils. Consider the simple flow path along a curved plate shown in the figure below. At point A the flow field is unperturbed by the presence of the airflow and the local pressure is equal to the atmospheric pressure 
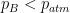
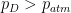

![Flow around a curved airfoil [2]](https://aerospaceengineeringblog.com/wp-content/uploads/2015/10/Untitled2.jpg)
Flow around a curved airfoil [2]
A couple of interesting observations follow from the above discussion. Nature typically uses thin wings with high camber, whereas man-made flying machines typically have thicker airfoils due to their improved structural performance, i.e. stiffness. In the figure below, the deep camber thinner wing shows highly curved flow in the same direction on both the top and bottom surfaces.

Deep camber thin wing with high lift [2]

Shallow camber thick wing with less lift [2]
The more shallow camber thicker wing has flow curved in two different directions on the bottom surface and will therefore result in less pressure difference between the top and bottom surfaces. Thus, for maximum lift, the thin, deeply cambered airfoils used by birds are the optimum configuration.
In conclusion, we have investigated a number of different theories explaining how lift is created around airfoils. Each theory was investigated in terms of the simplicity and validity of its underlying assumptions, and the diversity of phenomena it can describe. The theories based on Bernoulli’s principle, such as the equal transit time theory and the contraction of streamtubes theory, were either based on faulty initial assumptions, i.e. equal time, or failed to explain why streamtubes should contract or expand in the first place. The theory based on airfoils deflecting airflow downwards is theoretically accurate and correct (Newton’s third law: changes in fluid momentum over a control volume including the airfoil lead to a reactive lift force), but by being an integral approach it is not helpful in explaining what occurs between the leading and trailing edges of the airfoil (e.g. upwash is also a contributing factor to lift).
A more intricate theory is that curved bodies induce curved streamlines, as the inherent viscosity of the fluid forces the fluid to adhere to the surface of the body via a boundary layer. The centripetal forces that arise in the curved flow lead to a drop in pressure across the streamlines towards the centre of curvature. This means that if a body leads to asymmetric curved streamlines across it, then the induced pressure differential arising from the asymmetry induces a net lift force.
Edits and Acknowledgments
A previous version of this article referenced a misleading and incorrect example of a highly cambered airfoil as a counterexample to the theory of airfoils deflecting airflow downwards and the theoretical explanation using control volumes. Dr Thomas Albrecht of Monash University pointed this error out to me (see the discussion in the comments) and his contribution in improving the article is gratefully acknowledged.
Photo credit
[1] DThanhvp. Photobucket. http://s37.photobucket.com/user/DThanhvp/media/American.jpg.html
[2] Babinsky, H. (2003). How do wings work?. Physics Education 38(6) pp. 497-503. URL: http://iopscience.iop.org/article/10.1088/0031-9120/38/6/001/pdf;jsessionid=64686DBCB81FEB401CFFB87E18DFE6DA.c1
The name we use for our little blue planet “Earth” is rather misleading. Water makes up about 71% of Earth’s surface while the other 29% consists of continents and islands. In fact, this patchwork of blue and brown, earth and water, makes our planet very unlike any other planet we know to be orbiting other stars. The word “Earth” is related to our longtime worldview based on a time when we were constrained to travelling the solid parts of our planet. Not until the earliest seaworthy vessels, which were believed to have been used to settle Australia some 45,000 years ago, did humans venture onto the water.
Not until the 19th century did humanity make a strong effort to travel through another vast sea of fluid, the atmosphere around us. Early pioneers in China invented ornamental wooden birds and primitive gliders around 500 BC, and later developed small kites to spy on enemies from the air. In Europe, the discovery of hydrogen in the 17th century inspired intrepid pioneers to ascend into the lower altitudes of the atmosphere using rather explosive balloons, and in 1783 the brothers Joseph-Michel and Jacques-Étienne Montgolfier demonstrated a much safer alternative using hot-air balloons.
The pace of progress accelerated dramatically around the late 19th century culminating in the first heavier-than-air flight by Orville and Wilbur Wright in 1903. Just 7 years later the German company DELAG invented the modern airline by offering commercial flights between Frankfurt and Düsseldorf using Zeppelins. After WWII commercial air travel shrunk the world due to the invention and proliferation of the jet engine. Until a series of catastrophic failures the DeHavilland Comet was the most widely-used aircraft but was then superseded in 1958 by one of the iconic aircrafts, the Boeing 707. Soon military aircraft began exploring the greater heights of our atmosphere with Yuri Gagarin making the first manned orbit of Earth in 1961, and Neil Armstrong and Buzz Aldrin walking on the moon in 1969, a mere 66 years after the first flight at Kittyhawk by the Wright brothers.
Air and space travel has greatly altered our view of our planet, one from the solid, earthly connotations of “Earth” to the vibrant pictures of the blue and white globe we see from space. In fact the blue of the water and the white of the air allude to the two fluids humans have used as media to travel and populate our planet to a much greater extent than travel on solid ground would have ever allowed.
Fundamental to the technological advancement of sea- and airfaring vehicles stood a physical understand of the media of travel, water and air. In water, the patterns of smooth and turbulent flow are readily visible and this first sparked the interest of scientists to characterise these flows. The fluid for flight, air, is not as easily visible and slightly more complicated to analyse. The fundamental difference between water and air is that the latter is compressible, i.e. the volume of a fixed container of air can be decreased at the expense of increasing the internal pressure, while water is not. Modifying the early equations of water to a compressible fluid initiated the scientific discipline of aerodynamics and helped to propel the “Age of Flight” off the ground.
One of the groundbreaking treatises was Daniel Bernoulli’s Hydrodynamica published in 1738, which, upon other things, contained the statement many of us learn in school that fluids travel faster in areas of lower than higher pressure. This statement is often used to incorrectly explain why modern fixed-wing aircraft induce lift. According to this explanation the curved top surface of the wing forces air to flow quicker, thereby lowering the pressure and inducing lift. Alas, the situation is slightly more complicated than this. In simple terms, lift is induced by flow curvature as the centripetal forces in these curved flow fields create pressure gradients between the differently curved flows around the airfoil. As the flow-visualisation picture below shows, the streamlines on the top surface of the airfoil are most curved and this leads to a net suction pressure on the top surface. In fact, Bernoulli’s equation is not needed to explain the phenomenon of lift. For a more detailed explanation of why this is so I highly recommend the journal article on the topic by Dr. Babinsky from Cambridge University.

Flow lines around an airfoil (Source: Wikimedia Commons https://en.wikipedia.org/wiki/File:Airfoil_with_flow.png)
Just 20 years after Daniel Bernoulli’s treatise on incompressible fluid flow, Leonard Euler published his General Principles of the Movement of Fluids, which included the first example of a differential equation to model fluid flow. However, to derive this expression Euler had to make some simplifying assumptions about the fluid, particularly the condition of incompressibility, i.e. water-like rather than air-like properties, and zero viscosity, i.e. a fluid without any stickiness. While, this approach allowed Euler to find solutions for some idealised fluids, the equation is rather too simplistic to be of any use for most practical problems.
A more realistic equation for fluid flow was derived by the French scientist Claude-Louis Navier and the Irish mathematician George Gabriel Stokes. By revoking the condition of inviscid flow initially assumed by Euler, these two scientists were able to derive a more general system of partial differential equations to describe the motion of a viscous fluid.

The above equations are today known as the Navier-Stokes equations and are infamous in the engineering and scientific communities for being specifically difficult to solve. For example, to date it has not been shown that solutions always exist in a three-dimensional domain, and if this is the case that the solution in necessarily smooth and continuous. This problem is considered to be one of the seven most important open mathematical problems with a $1m prize for the first person to show a valid proof or counter-proof.
Fundamentally the Navier-Stokes equations express Newton’s second law for fluid motion combined with the assumption that the internal stress within the fluid is equal to diffusive (“spreading out”) viscous term and the pressure of the fluid – hence it includes viscosity. However, the Navier-Stokes equations are best understood in terms of how the fluid velocity, given by 
The other terms in the Navier-Stokes equations are the density of the fluid 
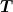


In simple terms, the Navier-Stokes equations balance the rate of change of the velocity field in time and space multiplied by the mass density on the left hand side of the equation with pressure, frictional tractions and volumetric forces on the right hand side. As the rate of change of velocity is equal to acceleration the equations boil down to the fundamental conversation of momentum expressed by Newton’s second law.
One of the reasons why the Navier-Stokes equation is so notoriously difficult to solve is due to the presence of the non-linear 
The complexity of the solutions should not come as a surprise to anyone given the numerous wave patterns, whirlpools, eddies, ripples and other fluid structures that are often observed in water. Such intricate flow patterns are critical for accurately modelling turbulent flow behaviour which occurs in any high velocity, low density flow field (strictly speaking, high Reynolds number flow) such as around aircraft surfaces.
Nevertheless, as the above simulation shows, the Navier-Stokes equation has helped to revolutionise modern transport and also enabled many other technologies. CFD techniques that solve these equations have helped to improve flight stability and reduce drag in modern aircraft, make cars more aerodynamically efficient, and helped in the study of blood flow e.g. through the aorta. As seen in the linked video, fluid flow in the human body is especially tricky as the artery walls are elastic. Thus, such an analysis requires the coupling of fluid dynamics and elasticity theory of solids, known as aeroelasticity. Furthermore, CFD techniques are now widely used in the design of power stations and weather predictions.
In the early days of aircraft design, engineers often relied on back-of-the-envelope calculations, intuition and trial and error. However, with the increasing size of aircraft, focus on reliability and economic constraints such techniques are now only used in preliminary design stages. These initial designs are then refined using more complex CFD techniques applied to the full aircraft and locally on critical components in the detail design stage. Equally, it is infeasible to use the more detailed CFD techniques throughout the entire design process due to the lengthy computational times required by these models.
Physical wind tunnel experiments are currently indispensable for validating the results of CFD analyses. The combined effort of CFD and wind-tunnel tests was critical in the development of supersonic aircraft such as the Concorde. Sound travels via vibrations in the form of pressure waves and the longitudinal speed of these vibrations is given by the local speed of sound which is a function of the fluids density and temperature. At supersonic speeds the surrounding air molecules cannot “get out of the way” before the aircraft arrives and therefore air molecules bunch up in front of the aircraft. As a result, a high pressure shock wave forms in these areas that is characterised by an almost instantaneous change in fluid temperature, density and pressure across the shock wave. This abrupt change in fluid properties often leads to complicated turbulent flows and can induce unstable fluid/structure interactions that can adversely influence flight stability and damage the aircraft.
The problem with performing wind-tunnel tests to validate CFD models of these phenomena is that they are expensive to run, especially when many model iterations are required. CFD techniques are comparably cheaper and more rapid but are based on idealised conditions. As a result, CFD programs that solve Navier-Stokes equations for simple and more complex geometries have become an integral part of modern aircraft design, and with increasing computing power and improved numerical techniques will only increase in importance over the coming years. In any case, the story of the Navier-Stokes equation is a typical example of how our quest to understand nature has provided engineers with a powerful new tool to design improved technologies to dramatically improve our quality of life.
References
If you’d like to know more about the Navier-Stokes equations or 16 other equations that have changed the world, I highly recommend you check out Ian Stewart’s book of the same name.
Ian Stewart – In Pursuit of the Unknown: 17 Equations That Changed the World. Basic Books. 2013.
“Engineering is not the handmaiden of physics any more than medicine is of biology”
What is science? And how is it different from engineering? The two disciplines are closely related and the differences seem subtle at first, but science and engineering ultimately have different goals.
A scientist attempts to gain knowledge about the underlying structure of the world using systematic observations and experimentation. Scientists are experts in dealing with doubt and uncertainty. As the great Richard Feynman pointed out: “When a scientist doesn’t know the answer to a problem, he is ignorant. When he has a hunch as to what the result is, he is uncertain. And when he is pretty darned sure of what the result is going to be, he is in some doubt” [1]. The body of science is a collection of statements of varying degrees of certainty, and in order to allow progress, scientists need to leave room for doubt. Without doubt and discussion there is no opportunity to explore the unknown or discover new insights about the structure and behaviour of the world.
In the same manner, the role of the engineer is to explore the realm of the unknown by systematically searching for new solutions to practical problems. Engineering is less about knowing (or not knowing), and more about doing; it is about dreaming how the world could be, rather than studying how it is. Engineers rely on scientific knowledge to design, build and control hardware and software, and therefore apply scientific insights to devise creative solutions to practical problems.
I bring up this seemingly superfluous topic because even seasoned journalists can confuse, perhaps unwillingly, the differences between the two endeavours. This article in the Guardian about the recent landing of Philae on Comet 67P refers to the great success of “scientists” on multiple occasions, but fails to give due credit to “engineers” by referring to their role only once. So, is landing a machine on an alien body hurtling through space a scientific or an engineering achievement?
There is certainly no straightforward answer to this question. Both scientists and engineers were indispensable in the success of the Rosetta program. However, in paying credit to the fantastic achievement of engineers involved in this space endeavour, I will leave you with this brief letter by three University of Bristol professors, that so poetically captures the essence of engineering:
Landing Philae on Comet 67P from the Rosetta probe is a fantastic achievement (One giant heartstopper, 14 November). A tremendous scientific experiment based on wonderful engineering. Engineering is the turning of a dream into a reality. So please give credit where credit is due – to the engineers. The success of the science is yet to be determined, depending on what we find out about the comet. Engineering is not the handmaiden of physics any more than medicine is of biology – all are of equal importance to our futures.
– Emeritus professor David Blockley, Professor Stuart Burgess, Professor Paul Weaver, University of Bristol
References
[1] “What Do You Care What Other People Think?: Further Adventures of a Curious Character” by Richard P. Feynman. Copyright (c)1988 by Gweneth Feynman and Ralph Leighton.
